
Tech Topic | June 2016 Hearing Review
This study examines the effectiveness of the Widex Unique™ wind noise attenuation algorithm. The data suggests the WNA algorithm significantly reduces annoyance and at the same time increases speech understanding, representing a marked improvement in the industry. The fact that a WNA algorithm can isolate wind noise regardless of its azimuth is a powerful new advantage.
Advanced research in hearing aid algorithm development has focused on speech understanding in adverse listening conditions. Innovative designs with dual microphone technologies have brought remarkable progress in noise reduction that enhances overall speech perception in background noise. Behind-the-ear (BTE) instruments allow multi-microphone technology to thrive, and breakthroughs in miniaturization of BTE aids and open-fit technology have made BTE fittings widely acceptable—and the preferred style for hearing care professionals in recent years, making up 77% of all hearing aid fittings in 2015.1
A downside of the BTE instrument is its inherent placement of the microphones. This microphone placement is susceptible to wind noise at the input of the microphone, which is created by random turbulence at the end of the microphone port. Compared to other styles of hearing instruments, BTE fittings have the least benefit from the natural contour of the pinna and concha, and hence are most susceptible to wind noise.
The long-term-average wind-noise spectrum varies with not only the style of hearing aids, but also the wind speed and azimuth.1 While this phenomenon was discussed over two decades ago, BTE fittings were not nearly as prevalent then as they are today; consequently, limited research was directed to this matter. As our society continues to promote hearing healthcare as critical to the overall quality of life, individuals are increasingly interested in hearing aids because of their active lifestyle. This population enjoys outdoor recreation, including jogging, biking, golfing, and sailing. Their utilization of BTE instruments means that wind noise is now of primary concern.
New research has emerged in the past decade that addresses wind noise and wind speed3—as well as working memory, listening effort, and cognition4,5—in reference to effects on speech understanding. The current belief is that speech processing involves the individual’s working memory to a large degree. Because working memory capacity is limited, listening in wind noise or in any adverse condition consumes it quickly; therefore advancements in noise reduction will ultimately divert additional working memory towards speech understanding.
Advancements in digital platforms have allowed innovative noise reduction algorithms to emerge. Designers of digital noise reduction algorithms have considered reducing listening effort as a primary goal to optimizing speech understanding. Rönnberg et al6 reported the importance of working memory capacity in language processing. Their research has documented that additional working memory is consumed when processing speech in noise. Hence, increased ease of listening in noise would allow additional working memory capacity and improved language processing ability in noise.
As wind noise has become a major concern with BTE instruments, continued effort has targeted advancing wind-noise reduction algorithms. This paper reports on the effectiveness of the Widex Unique™ wind noise attenuation (WNA) algorithm.
Background
Wind noise. Air flow can be categorized as either laminar (without resistance) or turbulent (with resistance). When there is no obstruction, air flows smoothly across a surface as a laminar flow field. However, if the air flows across any resistance or obstacle (such as the end of the microphone port, or a deflection from the pinna), it creates turbulence known as turbulent flow. These turbulences, when picked up by a microphone, are what we refer to as wind noise. The higher the velocity of air turbulence flow across the microphone port, the greater the wind noise level. The air turbulences created by the strongest wind can drive the microphone to saturation (mainly in the low frequencies range) and result in severe distortion.
In general, the long-term-average wind spectrum has similar contours as the level increases.7 Wind noise, a form of 1/f noise, is predominantly low frequency and diminishes at higher frequencies. Our perception, however, may interpret the higher wind speed as contributing more to higher frequencies.8 This can be explained by the minimal audible pressure curves indicating that change of loudness growth contour is more significant in high frequencies than in low frequencies. Furthermore, Dillon et al2 reported head effects on wind turbulence were at low frequencies (<~1000Hz), and pinna effects contributed to mid-frequencies (<~3000 Hz) region.
Annoyance. Turbulent noise is usually perceived as annoying and unacceptable when it exceeds subjective tolerance levels, which contributes to hearing aid dissatisfaction and negatively impacts speech understanding. Kochkin9 in his MarkeTrak study reported wind noise was rated at 58% satisfaction. While this represents a significant improvement from the past, it still remains the 2nd major concern amongst hearing aid users.
Acceptable noise level has been investigated in reference to ease of listening,10 as well as annoyance, as was used in this study. Acceptable noise factor may not directly interfere with speech understanding; however, it has been shown to affect listening comfort. It is important to realize that listening comfort is compromised in adverse listening situations where speech intelligibility is important. Therefore, listening for comfort and listening for speech intelligibility have different parameters. Research has shown that speech or language understanding is highly associated with an individual’s cognition and working memory.11 Therefore, listening for intelligibility requires a higher working memory capacity than comfort listening. This also explains why hearing aid users may prefer a comfort listening setting as their primary program and compromise listening programs for intelligibility or speech understanding.
In order to combine both scenarios, one has to bridge comfort listening and listening for intelligibility—without sacrificing either. In the Widex literature, Effortless Hearing has emerged to address this notion.
Working Memory Capacity (WMC). Working memory handles our memory and attention, and deciphers various language processing schemes for speech understanding.6 Research has indicated listening in noise preoccupies WMC, subsequently reducing capacity for speech understanding.12 Likewise, listening in high annoyance conditions limits our WMC towards speech understanding, which increases communication difficulties. Therefore, it is believed that Effortless Hearing is critical amongst listeners with hearing impairment who experience reduced cognitive capability when listening in noise environments.
Effects of wind noise on speech understanding have been explored in the field of cognitive neuroscience.4,13-15 The research has found that complex phonological analyses of speech due to lexicon or adverse listening situations require higher working memory. Similarly, wind noise is an adverse listening condition, and speech understanding under such conditions would presume higher working memory.
Conventional Wind Noise Algorithms
Directional microphone (2 ports) systems in digital hearing aids have become a predominant strategy to tackle speech understanding in background noise. The inherent design of a directional microphone has a -6dB/octave slope in the low frequencies. Hearing aid designs have traditionally compensated for this loss by adding a 6dB/octave gain in the low frequencies. While low frequencies may not contribute much to speech intelligibility (according to articulation index schema), they do affect comfort in listening. This strategy, however, conflicts with the spectral characteristics of wind noise. As 1/f noise is concentrated in the low frequencies and can saturate the microphone output with a 5m/s wind speed at 90-100 dB SPL,2 it is detrimental to provide gain at low frequencies.
Hence, the traditional wind-noise-reduction algorithms have optimized a two-microphone system, and applied a 2-stage (detection and reduction) process. If the analyses of the input signals from the two microphones are deemed correlated, then it is assumed to be speech; and if uncorrelated, the signals will be assumed to be noise. Once uncorrelated signals are detected, the operational mode is switched from directional microphone to omnidirectional microphone, and the gain in the low frequency region is reduced, affecting both speech and non-speech signals. Some algorithms utilize the spectrum characteristics of the uncorrelated signal to modify gain and yield a better signal-to-noise ratio (SNR).
The Unique Wind Noise Algorithm
With the advent of new digital technology, the Widex Unique hearing instrument utilizes two different reduction algorithms to compensate for both wind noise, utilizing a wind noise attenuation (WNA) algorithm, and soft level noise, utilizing a soft level noise reduction (SLNR) algorithm, to optimize Effortless Hearing.16 This system has four independent 18-bit analog-to-digital (ADC) converters that allow parallel programming capability. The new technology incorporates a 16 KHz frequency response range with 108 dB dynamic range. This allows the input dynamic range to extend from 5 dB SPL up to 113 dB SPL. For the SLNR algorithm, low level (<62 dB SPL) input signals are coded as speech versus non-speech; the soft speech signals are enhanced, and the low-level non-speech signal (such as refrigerator noise and fan noise) are further reduced.
The WNA is also a 2-stage process, mainly detection and reduction, that activates under wind noise conditions. With the increased capacity of the new digital chip, the Widex Unique instruments, under wind noise conditions, are now able to extract the correlated signals using an adaptive least-mean-square (LMS) filter system, and in addition to the gain algorithm to optimize Effortless Hearing. In other words, the uncorrelated signals (assumed to be noise) will no longer be in the representation or be considered because of the LMS filtering algorithm. This makes the WNA algorithm significantly more effective.
Research Goals
Recent research was conducted at ORCA-USA to examine the effectiveness of its wind noise attenuation (WNA) algorithm and the annoyance index of the wind noise. The purpose was to verify the findings of the pilot study, using similar protocols and parameters. The present paper examines the efficacy of the Widex WNA algorithm that incorporates “Effortless Hearing” in a Widex Unique hearing instrument as one of the primary goals to optimize speech understanding.
Each subject participated in two experiments for 90 minutes. In Experiment 1, subjects were asked to repeat words they heard via insert headphones. These words were recorded under various environments (4 speech levels, 5 wind speeds, and 2 azimuth conditions) in a wind tunnel. In Experiment 2, subjects were asked to rate the annoyance of the recorded wind noise. The wind noise samples were recorded at 5 different wind speeds and 2 azimuth conditions.
Study Methods
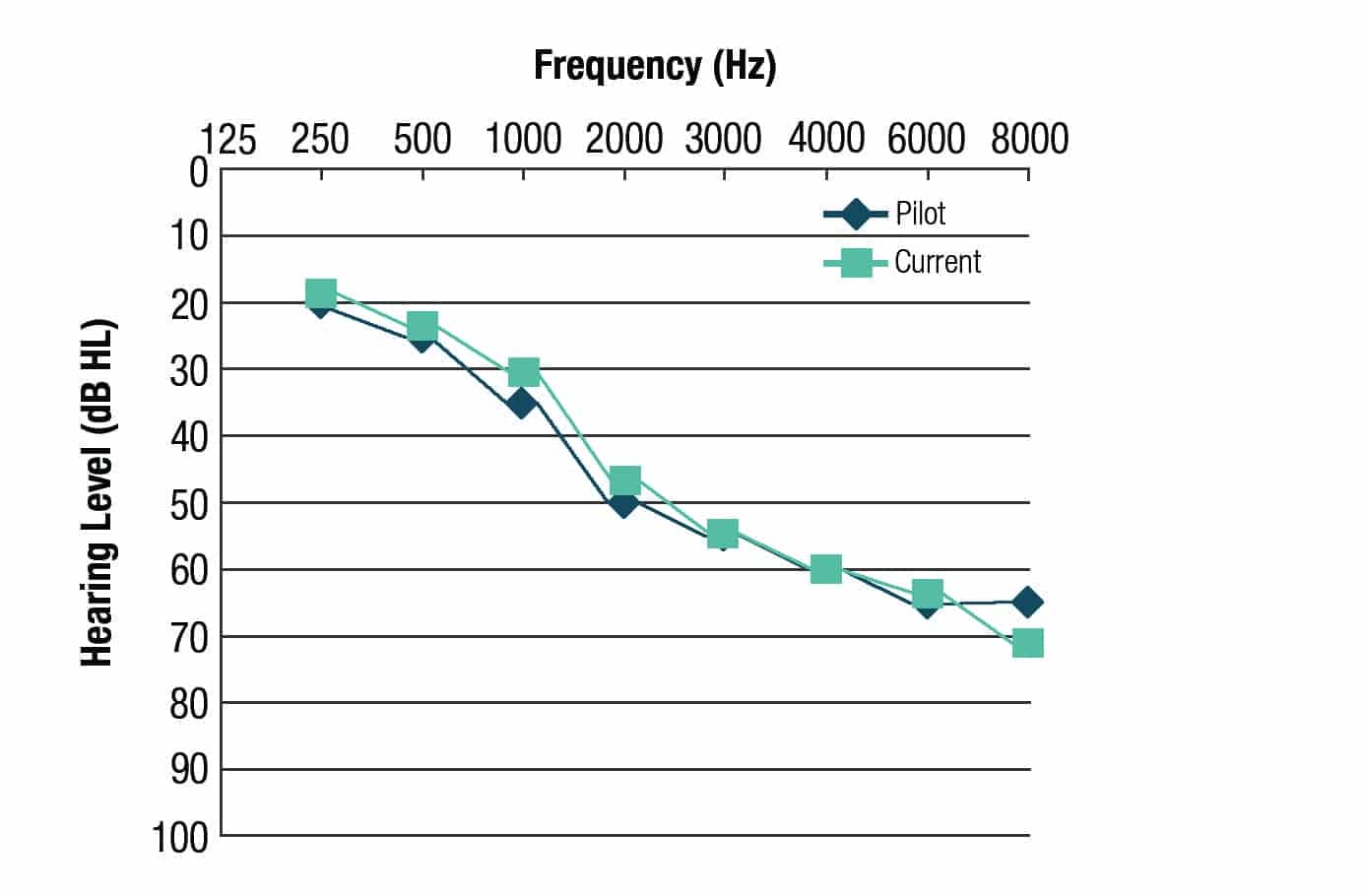
Figure 1. Average audiometric data of subjects participating in the pilot study and the current study.
Subjects. A total of 10 adults with a bilateral, mild to moderately severe sensorineural hearing loss participated in this study. All participants were Native American English speakers. Eight had at least 6 months experience with bilateral hearing aids, and 2 were new hearing aid users. The average test-ear thresholds were matched within a 10-dB range of the pilot study (Figure 1). This is critical because the stimuli used in this experiment were recorded based on the average hearing loss of the pilot study. All participants were informed of the purpose of the study, signed consents were obtained, and all were financially compensated for their time.
Experiment 1. An ORCA Nonsense Syllable Test17 was used to evaluate phoneme identification performance. This test utilized 25 consonants and five vowels, resulting in 115 nonsense words in a CVCVC format that focused on high-frequency speech sounds. Each consonant appeared at least once in the initial, medial, and final word positions unless prohibited by phonotactic constraints. Each nonsense word was then recorded through KEMAR in a wind tunnel (wind originated from 0° at a wind velocity of 5m/s, with speech presented from 90° at 4 different speech levels), with an NAL-NL2 prescription program based on the average hearing loss of the subjects from the pilot study. A custom computer program, with the recorded words and the wind noise provided by ORCA-USA, was used in this study. All signals were routed through a GSI 61 audiometer and presented monaurally to each subject using insert (ER3) headphones.
Each subject underwent 8 subtests: Four speech levels (60, 65, 70, and 75 dB SPL) with a WNA algorithm (on and off) in an IAC sound booth. Each subtest consisted of 32 nonsense words carefully selected from the list of 115. The subjects were asked to verbally repeat the word as heard, and their answers were phonetically transcribed by the experimenter and recorded onto a computer. The order of presentations among the subtests was randomized. The aggregated overall percent-correct phoneme identification scores across all subjects were analyzed. The overall score was subcategorized as consonants only and vowels only for further analyses.
Experiment 2. Noise stimuli were used to measure the subjective annoyance rating of each subject. The stimuli were pre-recorded in a wind tunnel with KEMAR at GRAS Sound & Vibration A/S in Holte, Denmark. Detail of the recordings can be found in Korhonen et al.18 Each subject listened to stimuli recorded at different azimuths (0° and 70°), and at different wind speeds (4, 5, 6, 7, and 10 m/s) with the WNA algorithm (on and off). All stimuli were routed through a GSI 61 audiometer and presented monaurally to each subject using insert (ER3) headphones.
Results
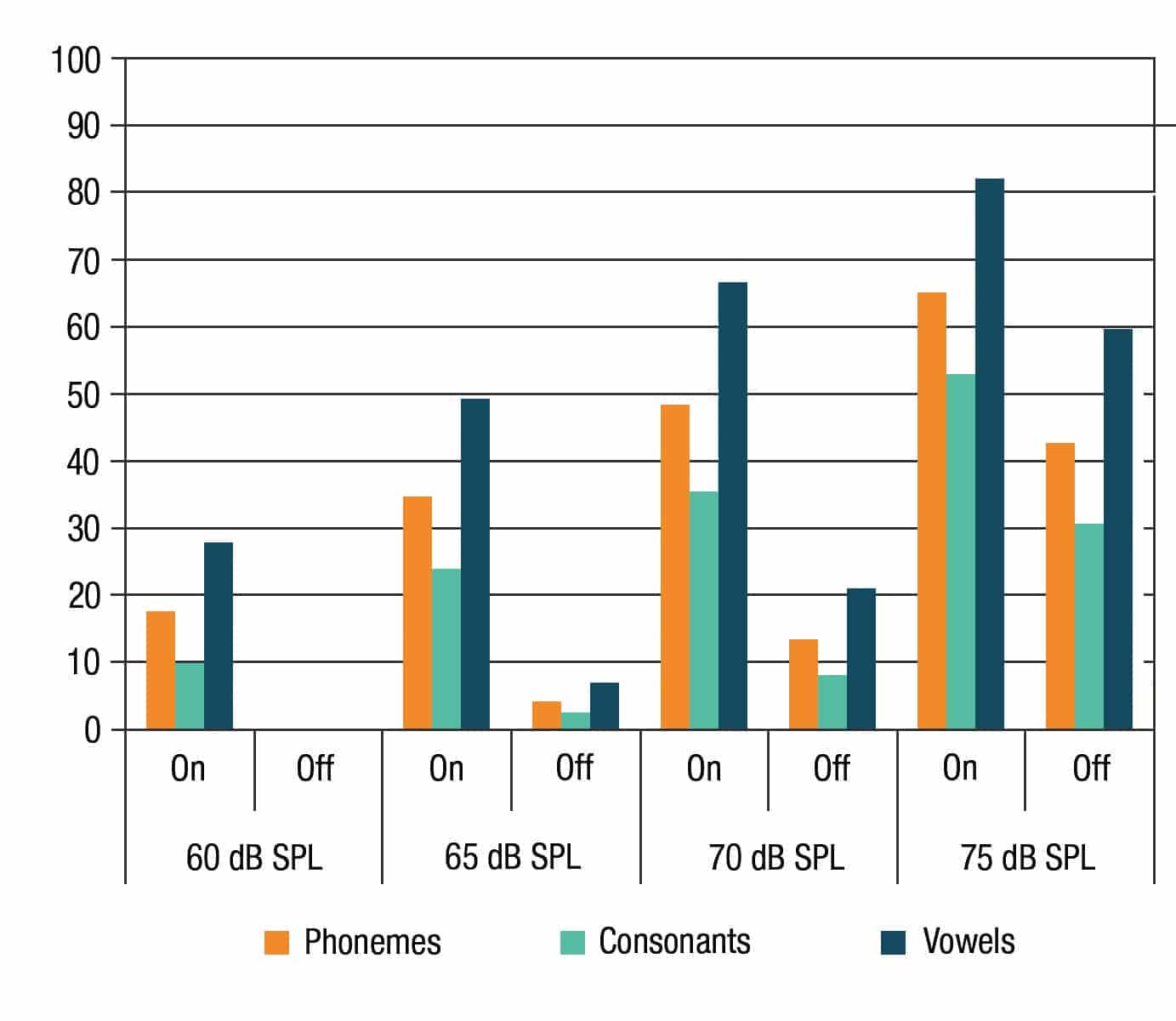
Figure 2. Average identification performance data across all subjects. The X axis represents all subtests (4 levels and 2 WNA settings). The Y axis represents the identification performance (%) of the phonemes (orange), and its subcategories: consonants (light blue) and vowels (dark blue).
Experiment 1. Descriptive mean data of all subjects are shown in Figure 2. The aggregated data of all stimuli were presented as the “phonemes” category; its subcategories were “consonants” and “vowels.” The X axis represents sound levels at 60, 65, 70, and 75 dB SPL with WNA algorithm (on and off). The Y axis represents the identification performance (%). The results show the performance identification scores across all subjects were better with WNA algorithm on at all four listening levels for phonemes, and its subcategories of consonants and vowels.
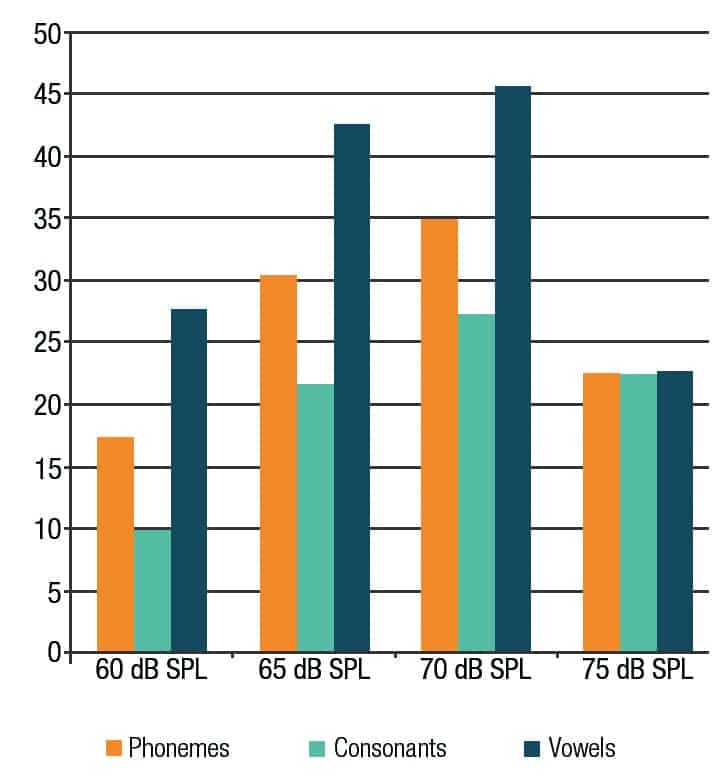
Figure 3. Identification performance improvement data across all speech levels as a function of phonemes (orange), consonants (light blue) and vowels (dark blue). The X axis represents the four speech levels. The Y axis represents the identification performance improvement (%) scores.
Figure 3 illustrates the difference in score (%) of the identification performance (WNA-on minus WNA-off) of the various phonemes categories and speech levels. It shows that the Widex Unique WNA provides significant improvement for the overall phonemes identification at all four speech levels ranging from 17% to 35%; consonants improvement ranged from 9% to 27%, and vowels improvement ranged from 22% to 46%.
Repeated measures ANOVA were administered to compare the phoneme identification performance of WNA (on vs off) at four different speech levels and under the different phonemic categories (all phonemes, consonants only, and vowels only).
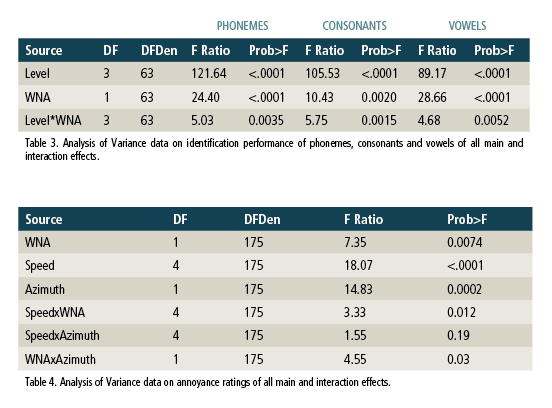
In summary, overall sound identification with WNA-on was consistently and significantly better than with WNA-off at all four speech levels for all phonemic categories. The data supported that the WNA algorithm developed by Widex has significantly enhanced phoneme identification in this specific wind noise environment.
Experiment 2. The median annoyance ratings were reported at various wind speeds. Figure 4 shows the effectiveness of WNA-on (solid line) vs WNA-off (dotted line) at two azimuths (left panel for 0° and right panel for 70°). The improvement is shown by the distinct gap between the solid and dotted lines.
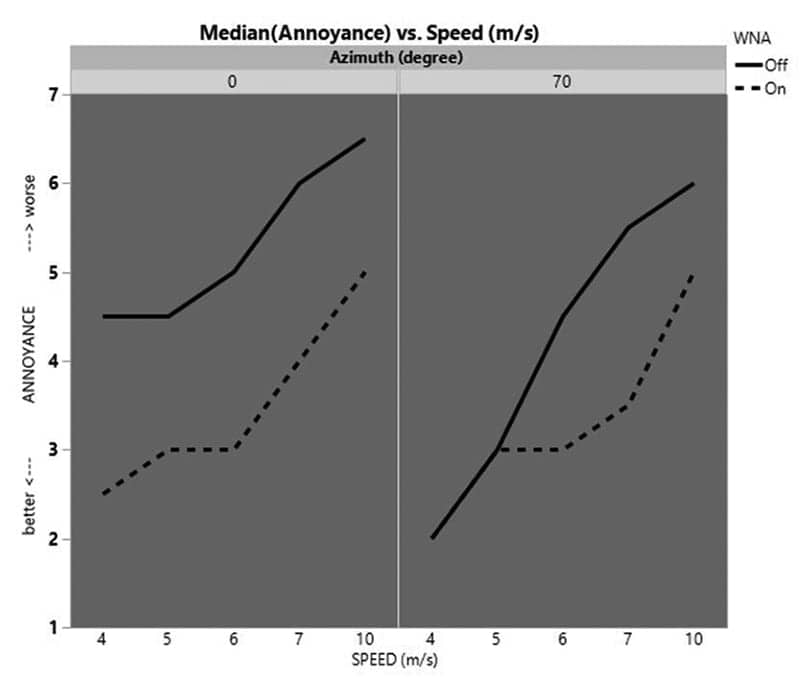
Figure 4. Median annoyance ratings across all subjects at various wind speed (m/s), as a function of WNA. The left and right panels represent 0° and 70° respectively. The solid line (WNA-off) and the dotted (WNA-on) lines illustrate the effect of WNA. The separation of the two lines shows the advantage with WNA-on at the different azimuths.
The results indicate significant improvement with WNA-on as less annoying for all wind speed and azimuth conditions, except two occasions: azimuth 70° at 4m/s and 5m/s, where the data showed no preference. Comparing the two azimuths, the ratings for frontal wind (0°) were higher (more annoying) than at 70°. However, the improvement with a WNA algorithm was consistent across the various wind speeds. At low wind speed (4 and 5 m/s) and at 70° when annoyance rating was at 3 or below, WNA was not critical.
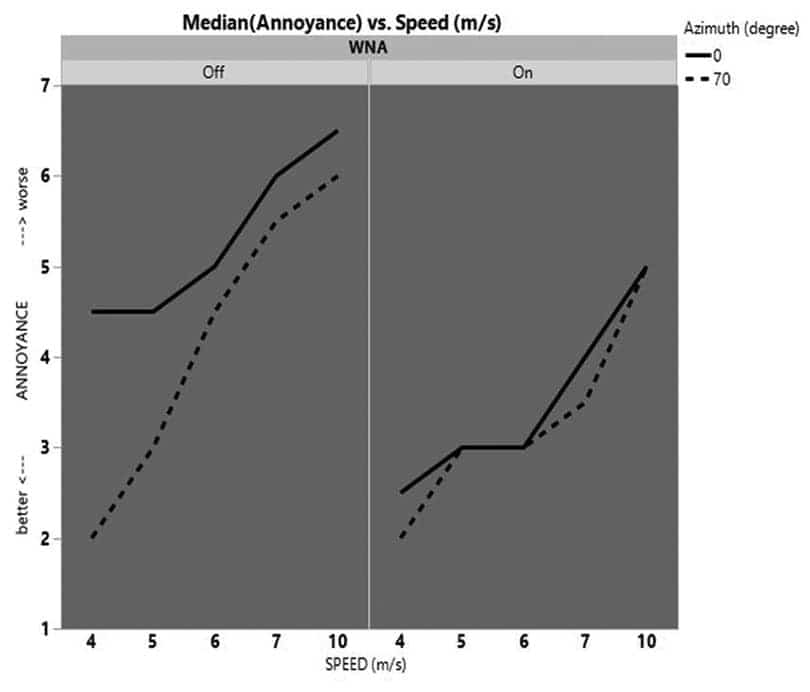
Figure 5. Median annoyance ratings across all subjects at various wind speed (m/s), as a function of azimuth. The left and right panels represent WNA off and on respectively. The solid line indicates WNA off, and the dotted line indicates WNA on. The closeness of the two lines, in particular with WNA-on, illustrates that azimuth is not a determinant factor with this algorithm.
Similarly, Figure 5 reports the same annoyance rating; however, it highlights the effect of azimuth with WNA on. The annoyance ratings almost overlap at the two azimuths when WNA is on. This illustration indicates, once the noise was detected, the algorithm was equally effective at both azimuths studied.
Analysis of Variance (Table 4) utilizing JMP Pro 12 was administered to compare the annoyance ratings across WNA (on and off), wind speed (4, 5, 6, 7, and 10 m/s), and azimuth (0° and 70°). Significant differences (p<.01) were observed at all main effects (WNA, speed and azimuth), and interactions (Speed x WNA and WNA x azimuth) at p<.05.
Discussion
The principle finding of this paper strongly supports the claim that speech perception in wind noise was improved with the Unique WNA algorithm. Experiment 1 showed that identification performance scores of phonemes and its subcategory consonants and vowels all improved with WNA “on” regardless of speech levels. Also noted was that vowel identification was better than consonant identification in all conditions. This was expected because of the upward spread of masking phenomenon that negatively affects higher frequency (consonant) signals more than for the lower frequency (vowel) signals.
Also noted, median annoyance ratings were not affected by the wind azimuth when the WNA algorithm was on (Figure 5) at all wind speed categories. If frontal wind was reported to be most disturbing, as shown by Dillon et al,2 this finding would suggest the WNA algorithm is very effective and is transparent to change in azimuth.
As annoyance is one of the many elements of the “Effortless Hearing” scheme in the Widex Unique, it is a step forward in the goal to reduce working memory usage in order to allow additional complex language processing to occur. This advantage is important for many hearing aid users, particularly those who engage in outdoor activities and inevitably encounter various breezy or windy conditions.
The fact that the WNA algorithm significantly reduces annoyance and at the same time increases speech understanding is a marked improvement in the industry. The fact that a WNA algorithm can isolate wind noise regardless of its azimuth is a powerful advantage. The result should be that hearing aid users are more relaxed as they transition from indoor to outdoor activities without having to be concerned about sacrificing their comfort of listening and communication.
Acknowledgement
This work was supported in part by Widex Inc. The author wishes to thank Annette Shiley for her assistance in data collection.
References
-
Hearing Industries Assn. HIA statistical reporting program, 4th Quarter 2015. Washington, DC: HIA; Jan 2016.
-
Dillon H, Roe I, Katch R. (1999). Wind noise in hearing aids: mechanisms and measurements. National Acoustics Labs Australia: Report to Danavox, Phonak, Oticon and Widex. January 13, 1999.
-
Chung K, Mongeau L, McKibben N. Wind noise in hearing aids with directional and omnidirectional microphones: polar characteristics of behind-the-ear hearing aids. J Acoust Soc Am. 2009;125(4): 2243-2259.
-
Arlinger S, Lunner T, Lyxell B, Pichora-fuller MK. The emergence of cognitive hearing science. Scand J Psychol. 2009;50:371-384.
-
Pichora-Fuller MK, Schneider BA, Daneman M. How young and old listens to and remember speech in noise. J Acoust Soc Am. 1995;97:593-608.
-
Rönnberg J, Lunner T, Zekveld A, Sorqvist P, Danielsson H, Lyxell B, Dahlstrom O, Signoret C, Stenfelt S, Pichora-Fuller MK, Rudner M. The ease of language understanding (ELU) model: theoretical, empirical, and clinical advances. Frontier in Systems Neurosci. 2013;July 13(7):31.
-
Barnard A. Flow induced noise reduction techniques for microphones in low speed wind tunnels. Sound Vibration. 2014;48(10):10-12.
-
Raspet, R., Webster, J. & Dillion, K. (2006). Framework for wind noise studies. J Acoust Soc Am. 119(2):834-43.
-
Kochkin S. MarkeTrak VIII: Consumer satisfaction with hearing aids is slowly increasing. Hear Jour. 2010;63(1):19.
-
Appleby R. Noise management in modern hearing aid fittings. Hearing Review. 2012;19(5):44-51.
-
Rudner M, Lunner T. Cognitive spare capacity and speech communication: a narrative overview. BioMed Research International. 2014;Article ID 869726. doi:10.1155/2014/869726. Available at: http://www.hindawi.com/journals/bmri/2014/869726
-
Meister H, Schreitmüller S, Grugel L, Beutner D, Walger M, Meister I. Examining speech perception in noise and cognitive functions in the elderly. Am J Audiol. 2013;22(2):310-312.
-
Farrell S, Wagenmakers EJ, Ratcliff R. 1/f noise in human cognition: Is it ubiquitous, and what does it mean? Psychonomic Bulletin & Rev. 2006; 13(4): 737-741.
-
Tun P. Fast noisy speech: age differences in processing rapid speech with background noise. Psychology Aging. 1998;13(3):424-434.
-
Wagenmakers EJ, Ratcliff R, Farrell S. Estimation and interpretation of 1/f noise in human cognition. Psychonomic Bulletin & Rev. 2004;11(4):579-615.
-
Kuk F, Schmidt E, Jessen AH, Sonne M. New technology for effortless hearing: A “unique” perspective. Hearing Review. 2015;22(11):32-36.
-
Kuk F, Lau C, Korhonen P., Keenan D. Development of the ORCA nonsense syllable test. Ear Hear. 2010;31(6):779-795.
-
Korhonen P, Kuk F, Seper E, Morkebjerg M. Evaluation of a wind noise attenuation algorithm on subjective annoyance and speech-in-wind performance. J Am Acad Audiol. 2016; In press.

Correspondence can be addressed to Dr Lee at: [email protected]
Original citation for this article: Lee L. Efficiency of a Wind Noise Attenuation Algorithm. Hearing Review. 2016;23(6):22.?


my left ear was 8 percent and I have————————– a cochlear device which is a challenge to learn, my right ear is at 45 percent! I hav bluetooth streaming from t v and I phone and also read close captioning. however we challenge because we change providers and the captioning on our new provider is no as clear! I am a Vetrans recipient, 100 percent disabled. do u think the V A will be a provider of your hearing aids?