Audiology & Neuroscience | July 2018 Hearing Review
The value of auditory event-related potentials for assessing listening effort
Every work day, in many audiology clinics in the United States, and, indeed, throughout the world, clinical speech audiometric measures are routinely administered to persons referred for audiometric assessment. The venerable 50-word PB lists are presented to each ear at suitable supra-threshold levels, and scores are duly noted. The rationale is that, in some way, these scores inform the clinician about the listener’s ability to understand what other people in the environment are saying. The distinguished speech scientist, experimental psychologist, and acoustician, Ira Hirsh put it succinctly in 1952:
True listening and everyday communication involve much more effort than just repeating words that have been heard. Might there be useful ways to think about quantifying listening effort by taking advantage of a considerable body of research on the auditory event-related potential (AERP)? In this article, Dr Jerger explores two different ways to think about clinical speech audiometry relative to assessing total listening effort: 1) Altering the task from repetition to decision, and 2) Evaluating the response evoked by the decision via an AERP paradigm.
“One of the reasons for considering the measurement of a person’s ability to hear speech is to fill in the gap between the audiogram and the person’s ability to communicate with his fellows in everyday life.” [italics added]1
Well, that is certainly what we all want, but how exactly did our antecedents plan to achieve this goal?
Historical Background
The father of clinical speech audiometry, Raymond Carhart,2 had no time for leisurely debate on the topic. He was the officer in charge of aural rehabilitation of hearing-impaired army personnel as they returned from WWII to the clinic at the army’s Deshon General Hospital—and they came by the truckload every working day.
The major part of his charge was to dispense hearing aids on a rational basis. Taking advantage of the word lists developed at the Harvard Psycho-Acoustic Laboratory during WWII, Carhart crafted a clinical procedure in which spondee words were employed to gauge the threshold below which no speech could be heard. Then the speech intensity was raised to a level 25 dB above that speech reception threshold (SRT) and a list of 50 words was presented to each ear. The listener’s task was to repeat back to the examiner each word as it was presented. Scoring was by correct repetition of the entire word.
Over the years, there were many efforts to relate these “PB-max scores” to successful human communication by language, but the relation remains elusive. It is perhaps noteworthy that Carhart, originally trained as a speech scientist, was guided by an essentially phonological approach to the analysis of communicative success. Speech understanding was achieved, he reasoned, when the listener was able to make fine distinctions among the different consonants and vowels, that is the ability to “discriminate” among closely similar phonemic elements of words (in the parlance of the busy clinician, PB scores are still called “discrim” scores). In his influential 1946 paper, “Tests for Selection of Hearing Aids,” under the heading “A Test of Discrimination,” Carhart wrote:
“The ability to distinguish small differences in sound is of primary importance to the hearing aid user. It is, therefore, necessary to have a good estimate of the relative discrimination which the wearer achieves with different hearing aids.” [p 786]2
But this philosophical orientation has never adequately explained the essence of Hirsh’s “ability to communicate with his fellows in everyday life.” 1
A Different Approach
Over the past seven decades, we have learned that there is a good deal more to successful listening in the real world than “the ability to distinguish small differences between sounds,” especially in the less-than-ideal acoustic environments often encountered by listeners. We now understand that there is an important further dimension (see sidebar) beyond behavioral indices like percent-correct scores or signal-to-noise ratios; it may be succinctly described as “listening effort.” This concept encompasses not only phonological, lexical, and semantic processing, but a number of cognitive resources affecting listening effort, including attention and memory, resources especially important in elderly persons. See, for example, the pioneering work of Pichora-Fuller and Singh3 in emphasizing the important interactions among bottom-up and top-down processes in actual listening environments as it impacts hearing aid use and aural rehabilitation.
A Systems Engineer’s 1960’s Critique of Speech Audiometry
In the 1960s, when I was pursuing research at The Houston Speech and Hearing Center, we had a VA contract to study successful hearing aid use in veterans via speech audiometry. Once every year the VA central office sent a person to monitor progress on the project.
Our monitor was Gene Murphy, a systems engineer. He didn’t know much about speech audiometry, he liked to say, but he knew a lot about how one tested systems. In essence, he said, you needed to know two things:
Where it breaks, and
How much stress it can take before it breaks.
He suggested that our PB scores were analogous to “where it breaks” (ie, incorrect words), but didn’t assess how much effort the listener had to exert in order to repeat the other words back correctly. Gene thought this a deficiency in our procedure.
I thought about that a lot, but, in the vanity of youth, did not question what we had always been taught. Years later, I learned about AERPs and recalled Gene’s admonition: You know whether the response was right or wrong, but you don’t know how difficult the listening was to get it right.
The present article asks the question, “Might there be useful ways to think about quantifying listening effort by taking advantage of a considerable body of research on the auditory event-related potential (AERP)?” The AERP is an addition to the well-known family of auditory evoked potentials (AEPs), including the auditory brainstem response (ABR), the middle latency response (MLR), and the late vertex response (LVR).
In AEP paradigms, a number of auditory stimuli are presented and the brain’s responses are averaged to display a waveform unique to the latency range under study. In the ABR—and to a certain extent the MLR and LVR—listeners need not respond to each stimulus presentation; indeed, they may pay little particular attention to any of them. In the AERP paradigm, however, the listener is presented with a task on every trial and must make a decision about what was heard.
P300: The First AERP
In the early days of research on the AERP, pioneered by Sutton et al,4 the listener heard a short tone burst on each trial. On most trials the frequency of the tone burst was at 1000 Hz (low pitch). On a much smaller number of trials, usually between 10% and 30% of total trials, the tone burst was at 2000 Hz (high pitch). These rarer events were considered “targets”; the more frequent events were considered “non-targets.” The listener’s task was to respond “yes” if the burst was high-pitched (target), but “no” if it was low-pitched (non-target). Significantly, the rarer high-frequency (target) tone evoked a clear positive deviation from baseline, peaking at a latency of about 300 msec after the tone burst onset. Therefore, it was initially named the “P300” peak. As advances in instrumentation permitted more difficult tasks, however, it soon became clear that, as task difficulty increased, the latency of the AERP became proportionately longer.
It is now widely accepted that this peak latency is associated with the process of making the decision that the rare stimulus was, indeed, a target. You might ask why both targets and non-targets do not each produce a P300 response, since both involve making a decision (ie, in the case of non-targets: “no, not a target”; in the case of targets: “yes, a target”). But that is not the case. Only stimuli identified as targets produce the characteristic P300 positivity. In the words of Terry Picton (2011)5:
“When only one of several equiprobable stimuli is considered a target, only this stimulus will evoke a P300 even though its actual probability is no different from that of the other stimuli. For example, Johnson and Donchin (1980)[6] presented three equiprobable tones, and had their subjects respond to only one. The designated target elicited a large P300 but neither of the other stimuli evoked more than a suggestion of a P300.”5
Finally, as evidence accumulated with more difficult tasks, the peak positivity, initially known as P300, was shown to increase in proportion to the intrinsic difficulty of the decision task. For this reason P300 has been renamed Late Positive Component (LPC) to take into account the fact that the latency of the positive peak in the oddball paradigm has been observed all the way from 300 to 900 msec.
All of this information about target responses in the oddball paradigm is well known and has been studied extensively. The interested reader is referred to Picton’s excellent book, Human Auditory Evoked Potentials.5
The AERP to Isolated Words
At our AERP laboratory at the University of Texas at Dallas, we spent more than 10 years studying the surface electrophysiology associated with the brain’s response to the auditory presentation of isolated words.7 Like so many other investigators, we employed the “odd ball” paradigm, at first, to study the late positive potential (LPP). In our work the stimulus was always a CVC word. We presented different words to the listener, one at a time, in blocks of 60 words. Most were randomly chosen from a body of CVC words, and had no particular relevance for the listener, but a small number of the 60 words, usually 15-20%, were all members of the same linguistic category. Target categories were usually the names of animals, articles of clothing, or eating utensils.
The listener’s task, after the presentation of each word, was to press a response button labelled YES, if the word was in the specified category, and to press a response button labelled NO, if the word was not in the specified category. We have called this a “category judgment” task. Responses to words in the specified category were considered “targets,” while responses to words not in the specified category were considered “non-targets.” This is, of course, a variation on the well-known “oddball paradigm,” but in which a small percentage of category words (for example, names of animals) are randomly interspersed among a much larger percentage of irrelevant words.
The result is that the brain generates a positive potential in response to target words, but not in response to non-target words. In the kinds of tasks we used in our research, the LPC latency usually fell in the 500-600 msec range. Not surprisingly, we typically found a strong LPC response to category-judgment tasks.
But…An Interesting Observation about Non-Target Words
When we examined our responses to target words, results were entirely predictable: there was a prominent positive peak in the waveform in the latency region of 500-600 milliseconds. But when we examined the non-target waveforms we noted a prominent negative peak at a latency in the 500-600 msec latency range, followed by a very slow return to baseline over the latency range from 1400 to 1800 msec.
This was somewhat unexpected. In much of the early work on LPC response, the signals were short pure-tone bursts. With this simple stimulus, there is very little processing of the non-target events. They are easily ignored. Hence it became standard practice to either subtract the non-target waveform from the target waveform, on the assumption that the expected response to non-targets would be a flat line at zero amplitude, or to simply ignore the non-target responses.
As we studied the processing of words rather than tone bursts, however, it became evident that there was a different story here. Non-target words appeared to undergo serious processing as well as the target words, but in a different way.
Now here is where it gets really interesting. In the case of a paradigm employing two short tone bursts differing only in frequency, the waveform of the target stimuli shows the expected LPC, but the waveform of the non-target stimuli is relatively flat: the more frequent non-targets appear to be scarcely processed at all.
But in the case of words, the picture is much more complicated. Every word—target or nontarget—is analyzed to produce, in the waveform, a relatively prolonged negativity, beginning at a latency of about 300 msec, peaking in the 500-600 msec latency range, then showing a prolonged return to the baseline of the waveform in the 1400 to 1800 msec range (not to be confused with the N400 response, evoked in an entirely different paradigm). We called this effect processing negativity or PN. Apparently, each word is processed phonologically, lexically, semantically, and cognitively.
Why doesn’t this PN component also appear in the target responses? It does, but is largely obscured by the algebraic addition of the much stronger positivity of the LPC in the same latency range.
The net result is that, by studying only non-target words, one may observe the actual processing of attended words without a confound introduced by the late positivity component.
The Nature of Processing Negativity
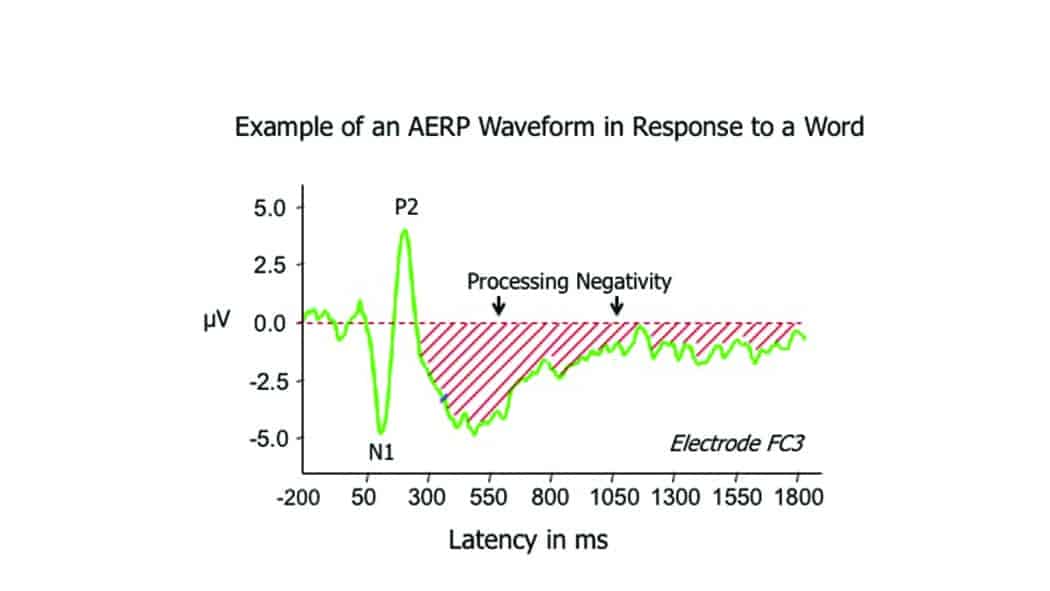
[Click on images to enlarge.] Figure 1. Example of an AERP waveform in response to the presentation of an isolated CVC word. The waveform was averaged over the non-target words in a category judgment task. The N1 and P2 peaks signal the initial detection of the auditory event. This is followed by a prolonged period of negativity, peaking in the 500-600 msec latency range and gradually returning to baseline in the 1400-1800 msec latency range. The red area can be devolved into separate components including phonological, lexical/semantic, and cognitive components.
What I am asking you, the reader, to do now is to put aside, for the moment, everything you may have learned about the LPC component of the AERP, the positive response to the comparatively rare target events, and consider how the negative response to the relatively more frequent non-target events may be exploited.
As we pursued this interesting phenomenon by means of independent component analysis or ICA,7 we were able to decompose the entire waveform generated by non-target responses into three presumably independent components:
- Initial detection of the word—reflected by the N1 and P2 peaks in the 0-300 msec range and centered over the Vertex (Cz) electrode;
- Phonological and semantic processing-reflecting processing negativity over the 300-1800 msec latency range, and
- Cognitive processing (principally memory and attention) reflected over the same range of processing negativity.
In the case of components #2 and #3, brain activity tends to be typically maximal at parietal electrode CP3, but extends forward to electrode FC3, reflecting activity over much of the left hemisphere.
Clearly there is a good deal going on over the latency range of processing negativity. We can devolve, over this extensive time period, not only phonological and semantic processing of the word but the simultaneous cognitive effort recruited to the total evaluation of the word.
How Might All This Be Relevant to Clinical Speech Audiometry?
Just repeating a word, or even a series of words, back to the examiner (repetition) does not adequately assess the breadth of linguistic and cognitive processes involved in genuine language processing. Consider the fact that you can easily repeat back words in many foreign languages of which you have absolutely no knowledge. For example:
- Say the word “taba” (“anklebone” in Spanish).
- Say the word “var” (“where” in German).
Dare I mention that parrots can do this too?
The act of repeating a word or a series of words says something about the success of the phonological analysis of the utterance, but tells us very little about the lexical/semantic analysis or the cognitive effort imposed especially by attentional and memory demands. To accomplish this goal you need to change the task from repeating to deciding. You need to force a decision from the listener rather than a simple repetition. Rather than simply repeating the word back, the listener must evaluate the percept, reach a decision, and make an appropriate response.
Repetition versus Category Judgment
In conventional speech audiometry, the instruction is to “repeat the word you heard.” Here, the listener’s analysis of the input phonology is referred immediately to the generation of an output phonology which configures the immediate verbal response. The word continues to be analyzed, however, by the listener’s brain via lexical/semantic analysis, leading to a linguistic concept, but the results of these latter stages play only a minor role in the listener’s repetition response.
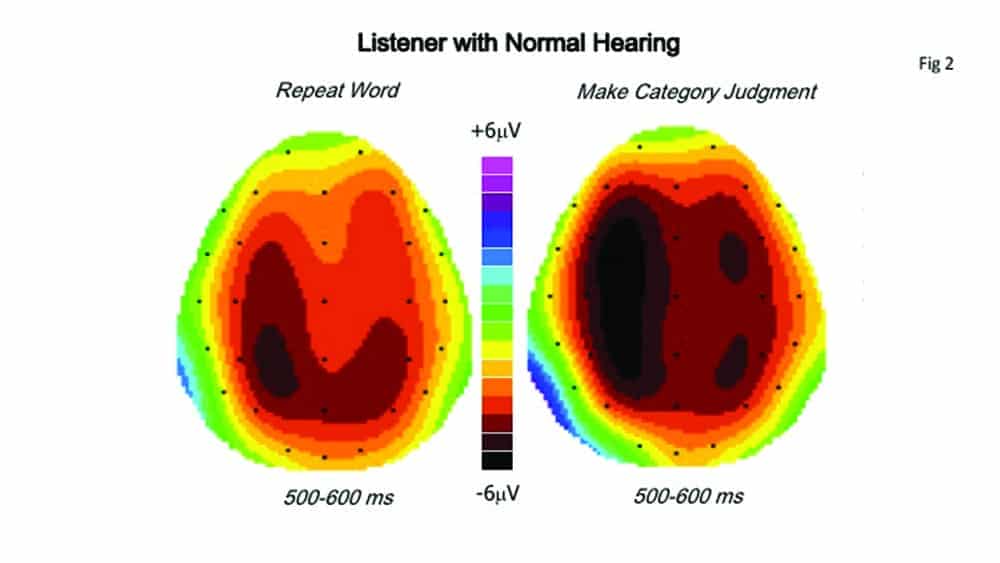
Figure 2. Comparison of AERP scalp topographies for simple word repetition versus category judgment in a younger listener with normal hearing, computed over the 500-600 msec latency range. Note, in the case of category judgment, a larger area of maximal activity over the left hemisphere and greater extension into the right hemisphere.
When, however, the instruction is to respond “yes” if the word is a target and “no” if the word is not a target, the ultimate response requires a decision based on the analysis. This analysis relies not only on the input phonology, but on the subsequent lexical and semantic analyses, and of the linguistic concept leading to the decision.
Forcing a decision based on the entire processing of the word invokes contributions from sources essentially ignored by the repetition paradigm. In the repetition, the presented word is analyzed for its input phonology, referred directly to the speech mechanisms to create an output phonology, leading to an appropriate verbal response. If, however, the listener must make a decision about the word, as in the category judgment paradigm, the input phonology is referred for further lexical/semantic analysis, leading to a word concept, leading to a decision, leading to an appropriate response. Reaching the ultimate decision involves the interplay among lexical/semantic analysis and the total cognitive effort, including at least attention and memory.
Figure 2 compares, in a young adult with normal hearing, the surface scalp topography of the AERP evoked by simply repeating each word (left map), and by forcing a decision about each word (right map). In the case of repetition, brain activity shows a small area of maximum amplitude over the CP3 electrode (black oval) surrounded by less amplitude (brown areas) extending forward to the region of FC3 and into the right hemisphere as far as parietal electrode P4. In the case of making a category judgment, however, the black area of maximal activity extends almost to electrode F3 over the left hemisphere, and the amplitude represented by the black and dark brown areas extends over the right hemisphere as far as electrode CP4. The greater brain activity in the category judgment task is evident.
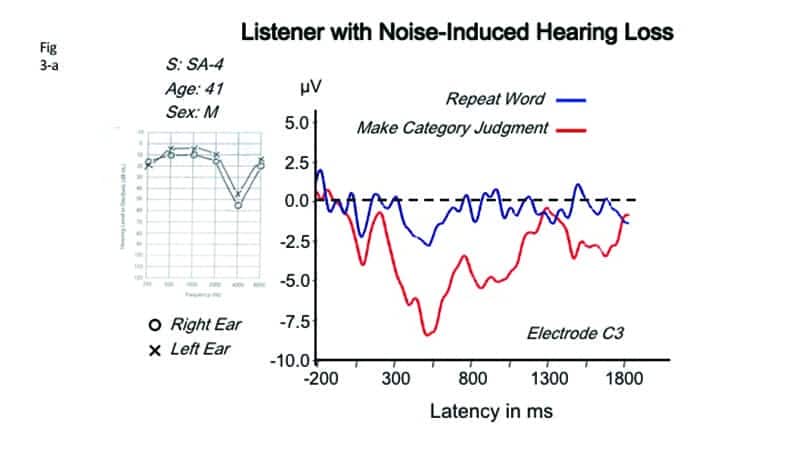
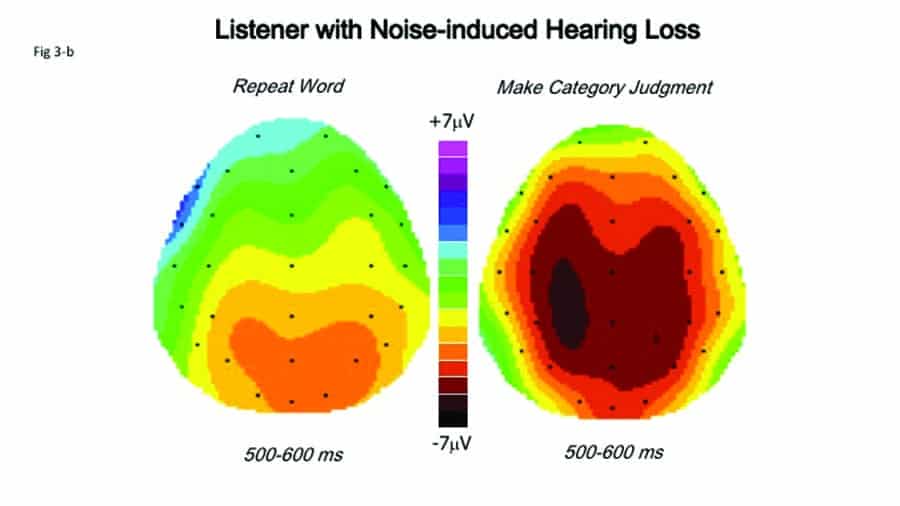
Figure 3a-b. Comparison of waveforms and AERP scalp topographies for simple word repetition versus category judgment in a 41-year-old listener with mild sensorineural hearing loss. Top Panel: Comparison of topographic brain maps computed over the 500-600 msec latency range. Note larger area of maximal brain activity over the left hemisphere and greater extension into the right hemisphere in the case of category judgments. Bottom panel: Audiogram and waveforms at electrode C3.
Figure 3 shows a similar comparison in a 41-year-old man with mild high-frequency sensorineural loss due to excessive noise exposure. Figure 3a (top panel) compares scalp topographies for both repetition and category judgment, computed over the 500-600 msec latency range. We see greater brain activity over both left and right hemispheres, but particularly greater over the left hemisphere, in the categorical judgment task. Figure 3b (bottom panel) shows the audiogram and, at electrode C3, waveforms for the two conditions. In the repeat-word condition (blue line), the waveform shows only a slight negativity of less than -2.5 microvolts in the 500 msec latency range, then returns quickly to baseline at about 800 msec. In the category-judgment condition (red line), however, negativity drops to more than -7.5 microvolts at about 600 msec, then returns gradually to baseline at about 1300 msec.
To Be Frank…
Although many audiologists have benefited from the use of the ABR for more than 40 years, the audiological world still has not fully benefited from the extensive research on AERPs over the past three decades. To be sure, it requires additional instrumentation and the fitting of at least a 32-electrode cap. It will, moreover, add significant additional time to the speech audiometric evaluation and to the review of the results. But the additional information gathered should, I believe, put a new perspective on clinical audiometric evaluation.
It is time to update our approach to speech audiometry by approximately 50 years. The additional information provided by implementing AERP evaluation will both widen and deepen speech audiometry evaluation, especially by telling us more about the total listening effort inherent in the actual processing of words.
Colleagues, we can learn so much more about how hearing loss and aging impact the actual evaluation of words by the brain. Why not give it a try? The payoff might be substantial!
Summary
In this article I have suggested two different ways to think about clinical speech audiometry in an effort to assess total listening effort: 1) Altering the task from repetition to decision, and 2) Evaluating the response evoked by the decision via an AERP paradigm. Particular emphasis has been placed on the processing-negativity (PN) component of the auditory event-related potential as a means for quantitative analysis of the listener’s mental effort in making decisions about isolated words.
Acknowledgement
This article was condensed from the Hallowell Davis Memorial Lecture presented at the annual meeting of the International Auditory Electric Response Study Group, New Orleans, 2013.
References
-
Hirsh I. The Measurement of Hearing. New York, NY: McGraw-Hill;1952:128.
-
Carhart R. Tests for selection of hearing aids. Laryngoscope. 1946;56(12):780-794.
-
Pichora-Fuller MK, Singh G. Effects of age on auditory and cognitive processing: Implications for hearing aid fitting and audiological rehabilitation. Trends Amplif. 2006;10(1):29-59.
-
Sutton S, Braren M, Zubin J, John ER. Evoked-potential correlates of stimulus uncertainty. Science. 1965;150(3700):1187-1188.
-
Picton T. Human Auditory Evoked Potentials. San Diego, CA: Plural Publishing; 2010:419.
-
Johnson R Jr, Donchin E. P300 and stimulus categorization: Two plus one is not so different from one plus one. Psychophysiology. 1980;17(2):167-178.
-
Jerger J, Martin J, Fitzharris K. Auditory Event-Related Potentials to Words: Implications For Audiologists. North Charleston, SC: CreateSpace Independent Publishing Platform, an Amazon Company; 2014.

CORRESPONDENCE can be addressed to Dr Jerger at: [email protected]
Reference for this article: Jerger J. Clinical speech audiometry in the age of the AERP. Hearing Review. 2018;25(7):14-19.
MORE ON “AUDIOLOGY & NEUROSCIENCE” from this special July 2018 edition of The Hearing Review:
- Clinical Speech Audiometry in the Age of the AERP, by James Jerger, PhD.
- Cortical Neuroplasticity in Hearing Loss: Why It Matters in Clinical Decision-Making for Children and Adults, by Anu Sharma, PhD, and Hannah Glick, AuD.
- Effects of Amplification on Cortical Electrophysiological Function, by Sridhar Krishnamurti, PhD, and Larry Wise, AuD.
- Cochlear implants: Considerations Regarding the Relationship between Cognitive Load Management and Outcome, by Edward Overstreet, PhD, and Michel Hoen, PhD.
- Dementia Screening: A Role for Audiologists, by Douglas L. Beck, AuD, Barbara R. Weinstein, PhD, and Michael Harvey, PhD, ABPP.



When ther person being tested isn’t sure if they’re heard the word correctly, there is effort required to decide whether or not to make a (wild) guess or just to say, “I didn’t hear that.”
how does that effort figure into the comparison?
….pardon my typos….