Tech Topic | October 2018 Hearing Review
Temporal envelope and temporal fine structure cues are complementary in nature, and both are used by listeners in their communications. Hearing loss, as well as the etiology and configuration of the hearing loss, could affect the relative importance of each cue for the listeners in their appreciation and understanding of daily sounds. This article reviews the importance of cues related to the temporal envelope and presents results of a study that compares the Widex EVOKE system, which is designed in part to preserve and enhance the temporal envelope, with another premium hearing aid.
Most of us are conditioned to think about sounds in terms of frequency and intensity when it comes to treating hearing loss. Examples of this behavior are reflected in our professional activities, such as measuring the degree of threshold loss at each frequency, the use of prescriptive gain targets, and the introduction of hearing aid technologies that allow for a broader bandwidth. There is a third dimension of sound that we are all aware of, but which is often overlooked—time. Indeed, how sound levels fluctuate over time (referred to as the “temporal envelope”) is an important cue for our understanding and appreciation of everyday sounds. This is especially true of speech and the emotion it conveys.
In this article, we will review the importance of the temporal envelope, and demonstrate how the EVOKE preserves or enhances the temporal envelope of the input.
What is the Difference Between Temporal Envelope and Temporal Fine Structure?
Any sound can be characterized in three dimensions: frequency, intensity, and time. Even on a 2-dimensional time-intensity display, the waveform of the sound actually includes information on all three dimensions.
Figure 1 shows the waveform of a short sentence. When we look at sound waveforms, we see the sound pressure changes over time. Some changes can occur very rapidly while others occur more slowly. Indeed, if we look at this waveform over a span of 2 s, we see large fluctuations in amplitude over time. If we zoom into a shorter time span, we still see that there is a lot of amplitude fluctuations within the shorter window. These fluctuations can be computed to determine the frequencies of the sound. Thus, a waveform not only includes information about changes in the intensity of the sound over time, but also about frequencies composing that sound.
The change in the overall amplitude of the sound, which includes how quickly it changes (ie, its modulation rate) and how much it changes (ie, its modulation depth), describes the sound’s temporal envelope. In Figure 1, the temporal envelope is represented by the red outline. The oscillations within the temporal envelope represent the sound’s temporal fine structure, or what we commonly refer to as the spectrum of the sound. So, we can actually say a sound includes two sets of information, the spectrum as represented by the temporal fine structure, and the temporal envelope as represented by how the amplitude of these frequencies changes over time.
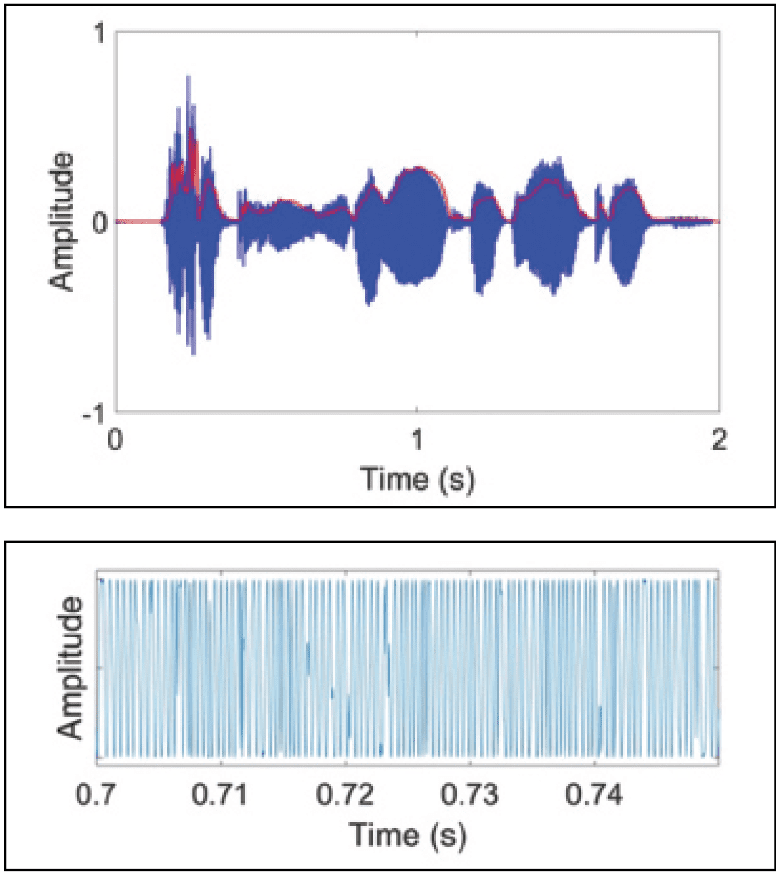
Figure 1. A 2-second wavefom of a sentence. The red outline is the temporal envelope of the sound. The temporal fine structure refers to the oscillations within the envelope of the sound of the same magnitude (ie, no variation in level). The fine structure has been magnified and shown on at the bottom.
What Information Does the Temporal Fine Structure and Envelope Provide?
Rosen1 classifies the rate of intensity fluctuations into three categories: envelope, periodicity, and fine structure. Temporal envelope refers to fluctuations in overall amplitude at rates between 2 Hz and 50 Hz (ie, slower fluctuations). It conveys segmental cues to the manner of articulation (eg, distinguishing between “shop” and “chop”), voicing (eg, distinguishing between “pool” and “bull”), vowel identity (eg, between /I/ vs /i/), as well as providing prosodic cues. In addition, it carries supra-segmental cues that allow one to distinguish differences in meaning and emotional intent of the speaker.2 More recently, information on the temporal envelope has been integrated into modulation-spectral features (MSFs) based models for the automatic emotional recognition of vocal speech signals.3
Periodicity refers to fluctuations at rates between 50 Hz and 500 Hz. Periodicity cues provide information on the source of excitation in speech production, and relate to the segmental information about voicing and the manner of speech production (eg, distinguishing between nasals and frication). It also conveys prosodic information about intonation and stress (eg, accenting on syllables, distinguishing between questions and statements and meaning in tonal languages).
Fine structure refers to variation of wave shape at fluctuation rates between 600 Hz and 10,000 Hz. Fine structure informs about the spectrum of the sound, including the formant patterns. It can also convey segmental information on place of articulation (eg, distinguishing between “bait,” “date,” and “gate”), vowel quality, and manner (eg, voiced sounds are more low frequencies and voiceless sounds are more high frequencies). Availability of the fine structure cues correlates to sound identity, sound quality, and has been reported to be important in speech understanding in noise.
Successful speech communication uses a combination of temporal envelope, periodicity, and fine structure cues. Different combinations of cues may also be used in music appreciation and the detection of emotions in speech. Table 1 summarizes the relative importance of each temporal cue in speech identification.

Table 1. Relative importance of each temporal cue for different linguistic contrasts. Size of stars reflects relative importance. Adapted from Rosen.1
Coding of the Temporal Fine Structure and Temporal Envelope
The auditory system begins to separate the incoming complex sound into its component frequencies at the level of the cochlea. Because the basilar member (BM) is 100 times stiffer and narrower at the base than at the apex, the traveling wave created by the sound induces maximum displacement towards the base of the BM for higher frequencies and towards the apex for lower frequencies. As such, stimulation of the hair cells underneath the base of the BM reflects high-frequency input, whereas stimulation of those near the apex reflects low-frequency input. Neurons receiving input from these hair cells convey this fine structure information upwards along the auditory pathway. Such “tonotopic” organization is known to exist at all levels of the auditory system.4
On the other hand, the temporal envelope is likely coded through a “pattern recognition” of activities across neurons. It is known that the amplitude of a sound is coded by an increase in the firing rate of the neurons and the number of neurons that are stimulated.4 Thus, the “peaks” and “valleys” seen over time in a waveform (ie, the envelope) could be coded as a pattern of synchronized neuronal activities along the auditory pathway. Indeed, it has been observed that different centers (or nuclei) of the auditory system respond to different modulation rates of the incoming sounds.5 Furthermore, Kubanek et al6 recently demonstrated that the belt area surrounding the auditory cortex tracks the temporal envelope of speech in humans.
Factors Affecting the Use of Temporal Envelope and Fine Structure Cues
Sensory hearing loss results from a loss of the hair cells and thus a loss of neuronal stimulation corresponding to the specific regions where the loss of hair cells occur. A direct consequence is that temporal fine structure cues related to those regions may no longer be available. This can lead to a loss of audibility, loss of frequency and temporal resolution, and to increased difficulty with speech understanding in noise.7 It is reasonable to expect that a more severe hearing loss results in a greater reduction of available fine structure cues.
On the other hand, because the temporal envelope is coded through patterned neural activity, it may be more resistant to hair cell loss. Indeed, Moore8 reported sensorineural hearing loss has no effect on monaural temporal processing, although it did affect binaural processing of the temporal envelope. However, the ability to utilize temporal envelope could be affected by disease processes where neural firing or neural synchrony is affected, regardless of a hearing loss.
One such factor is aging. For example, Gordon-Salant et al9 and Goupell et al10 reported that elderly individuals required longer temporal duration cues to distinguish between contrasts such as “dish/ditch” which differ in the duration of the silent interval. It is also reported that elderly individuals are poorer on temporal processing tasks, such as temporal gap detection and temporal modulation detection.11
Because both temporal fine structure and temporal envelope cues contribute to how the auditory system understands speech, a disruption in one set of cues may be offset or compensated for by the availability of the other set of cues. Auditory chimeras are useful for studying the relative importance or contribution of each set of cues. In this technique, envelopes of two sounds (eg, “cat” and “dog”) are separated from their fine structures. The envelope of one sound (eg, “cat”) is added to the fine structure of the other sound (eg, “dog”). The words are then presented to a listener for identification. If the listener’s response is “cat,” it is inferred that the envelope cues are used for the identification, whereas if the listener’s response is “dog,” then it is inferred that the fine structure cues are used for the identification.12
Liu and Zeng13 used this technique to study the relative contribution of envelope versus fine structure cues for conversational and “clear” speech (ie, speech spoken with greater temporal modulation and at a slower rate14). The authors reported that temporal envelope contributes more to the clear speech advantage at high signal-to-noise ratios (SNRs)—or quieter conditions—whereas the temporal fine structure contributes more at lower/poorer SNRs (noisier conditions).
Wang et al15 used the chimera technique to study the relative contribution of envelope and fine structure cues as a function of hearing loss severity in 22 normal-hearing and 31 hearing-impaired listeners. The temporal envelope of one Chinese monosyllable was paired with the fine structure of the same monosyllable of another tone (which makes it a different word). Thus, when the response was consistent with the first tone, it could be inferred that temporal envelope cues were used; whereas when the response was consistent with the second tone, then it could be inferred that fine structure cues were used. Their study showed that over 90% of the normal-hearing listeners’ responses were based on the fine structure cues. On the other hand, this reliance on fine structure cues decreased as the degree of hearing loss increased. Only 38% of the responses in subjects with a severe hearing loss were consistent with the fine structure cues. On the other hand, 7% of the responses from normal-hearing listeners were consistent with use of temporal envelope cues compared with nearly 44% of the responses from listeners with a severe hearing loss. This suggests that temporal envelope and fine structure cues are complementaryin nature. The reliance on temporal envelope increases when the availability of fine structure cues decreases, as is often a consequence of advancing hearing loss.16,17
In a later study, Wang et al18 used the chimera technique to study if individuals with auditory neuropathy spectrum disorder (ANSD) use temporal envelope and fine structure cues in the same way as people with a sensory hearing loss of similar magnitude (ie, matched degree of hearing loss). Compared to normal-hearing listeners, people with a SNHL have similar gap detection thresholds (a measure of temporal processing) but poorer frequency discrimination. On the other hand, people with ANSD have similar frequency discrimination as normal-hearing listeners, but a significantly poorer gap detection threshold (and presence of OAE and absence of ABR). The authors reported that people with ANSD had poorer tone-perception scores compared to those with a SNHL of similar magnitude. But, more importantly, the results showed that only 25% of responses from listeners with ANSD could be accounted for by temporal fine structure cues, whereas 45% of their responses could be accounted for by temporal envelope cues.
This suggests that for individuals with ANSD, the temporal envelope is an important cue that enables some degree of speech understanding. For this reason, attempts to preserve or enhance the temporal envelope of the incoming speech should provide better speech understanding. Indeed, Narne and Vanaja19 and Spirakis20 separately reported improved speech recognition in patients with ANSD through enhancement of the temporal envelope and use of slow-acting compression, respectively.
In summary, temporal envelope and temporal fine structure cues are complementary in nature. Both are used by listeners in their communication. Hearing loss, as well as the etiology and configuration of the hearing loss, could affect the relative importance of each cue for the listeners in their appreciation and understanding of daily sounds. In that regard, while hearing loss alone may be enough to reduce the availability of fine structure cues, coincident factors like aging, poor cognition, hearing loss severity, and ANSD could all aggravate the impact of limited fine structure information and increase the listener’s reliance on the temporal envelope cues. Thus, preservation—if not enhancement—of both sets of cues is important to ensure successful communication.
Improving Temporal Fine Structure and Envelope Cues
To the extent that a hearing loss is “aidable,” the use of amplification devices—especially ones with a broad bandwidth with minimal or no distortion—would be a solution to restore some of the fine structure cues. Signal processing methods, including noise reduction and directional microphones, that improve the audibility of the “speech” sounds in the presence of noise could also improve the audibility of the fine structure.
On the other hand, amplifying the incoming sounds may or may not preserve the temporal envelope of the incoming sounds. At least two hearing aid factors could affect the integrity of the temporal envelope.
1) Input and output limiting. Inputs that exceed the input limit of the hearing aid’s analog-to-digital converter (ADC) or output that exceeds the output limit of the hearing aid (OPSL90 or MPO) could be limited either by peak clipping or compression limiting, leading to a reduction of the natural difference between the louder and softer parts of the input (and output) and distortion of the temporal envelope. The impact may be even higher on the input side since this would also affect the accuracy of subsequent processing within the hearing aid. In that regard, the True Input Technology introduced by Widex since the DREAM has successfully raised the input limit to 113 dB SPL21 and has resulted in improved speech understanding22 and music appreciation.23
2) Multichannel compression hearing aids. Compression processing achieves its intended goal of better audibility and comfort by amplifying more of the soft sounds and less of the louder sounds. This “loudness equalization” could result in a processed output that is relatively unchanged in magnitude over time.
Thus, compression can reduce the dynamics of the input signal. Such reduction in temporal envelope dynamics is more pronounced in multi-channel compression devices,24,25 in those with a high compression ratio, and in those that use shorter time constants.26,27 More recently, it has been suggested that people with limited cognitive resources may benefit more from a compression hearing aid that uses longer time constants (ie, slow-acting compression) than shorter time constants (ie, fast-acting compression).28-30
How to Ensure Optimal Temporal Envelope
The EVOKE is designed to achieve Effortless Hearing by preserving (and enhancing when necessary) as much of the natural signals as possible. In addition to incorporating all the key features included in the UNIQUE and BEYOND hearing aids,31 the EVOKE is the first to introduce machine learning.32 The EVOKE also features enhancements to its dual variable-speed compressor (VSC) that further improve the temporal envelope of processed sounds.
Briefly, the VSC includes both a slow-acting compressor (SAC) and a fast-acting compressor (FAC) running in parallel in each of the 15 compression channels. The gain from both compressors are added to determine the final gain of the compressor. Under a typical situation, contribution from the slow compressor dominates to preserve the naturalness of the input signal. However, in a soft sound condition or when the input changes suddenly, contributions from the fast compressor increase.
Several design considerations further ensure that the VSC minimizes unnecessary reduction of the temporal envelope. First, FAC is used only when it is quiet or when the environment has a favorable SNR. Second, compressors in nearby channels are linked to minimize any smearing. Third, the VSC uses a low compression ratio (typically less than 2). Fourth, FAC is only applied for individuals who have less than a severe degree of hearing loss (< 75 dB HL). This is to ensure that these individuals are not deprived cues that they may be reliant upon for speech understanding.
VSC has been shown to be more responsive than adaptive compression.31 In addition, listeners wearing VSC hearing aids have been reported to show better intelligibility of soft sounds after a loud sound,33 and a lower sentence recognition threshold at an 85% recognition criterion.34 While the VSC in the EVOKE is based on the same principles used in the UNIQUE,31 the VSC algorithm in the EVOKE has been further fine-tuned in order to redistribute the relative contributions of the SAC and FAC across a wider range of listening scenarios.
The EVOKE Sound: Temporal Envelope
In order to examine the effect of the enhanced VSC algorithm (and other algorithms such as noise reduction, directional microphone, etc) on the temporal envelope of the input sounds, we compared the waveforms of the International Speech Test Signal (ISTS) in the following three hearing aid conditions:
1) Unaided condition.
2) Processed by the EVOKE in its default setting with a 40 dB HL flat hearing loss.
3) Processed by another commercial, state-of-the-art premium hearing aid (HA#A) that uses primarily fast compression (2 ms attack, 20 ms release) in its default setting with the same 40 dB HL flat hearing loss.
We also measured the waveforms in the following three test conditions:
1) Speech at 80 dB SPL input in quiet. This would allow an examination of the compressor action.
2) Speech at 80 dB SPL with a continuous speech-shaped noise at a SNR of +10 presented from the same direction as speech (ie, 00). This would allow an examination of the action of the VSC and any noise-reduction algorithm.
3) Speech at 80 dB SPL with a continuous noise at a SNR of +10 presented from the back (ie, 1800). This would allow an examination of the combined action of the VSC, noise-reduction, and directional microphone algorithms.
All measurements were done using KEMAR in a sound booth. Because the output from KEMAR varies with the HA condition (unaided was much lower in level than aided, and HA#A had a lower output than EVOKE), we scaled the display so they all had the same average output. This required us to magnify the display from the unaided condition by three times, and that of the HA#A by 1.5 times. We then lined all three hearing aid conditions on the same graph for easy comparison of temporal envelope changes. The following figures show a comparison of the three waveforms across a 1.5 s segment of ISTS signal taken from one minute into the recording.
Speech in quiet. Figure 2 compares the three HA conditions when the 80 dB SPL ISTS signal was presented in quiet. One sees that the blue curve (EVOKE) closely follows the red curve (unaided), suggesting that the EVOKE preserves the temporal envelope (of the unaided sound) well. In addition, it is also noted that some of the peaks exceed (near the first 0.1 to 0.4 s) and some of the valleys (near t = 0.7 s) of the EVOKE fall below that of the unaided condition (blue arrows). Overall, the EVOKE preserves the temporal envelope most of the time and enhances it somewhat.
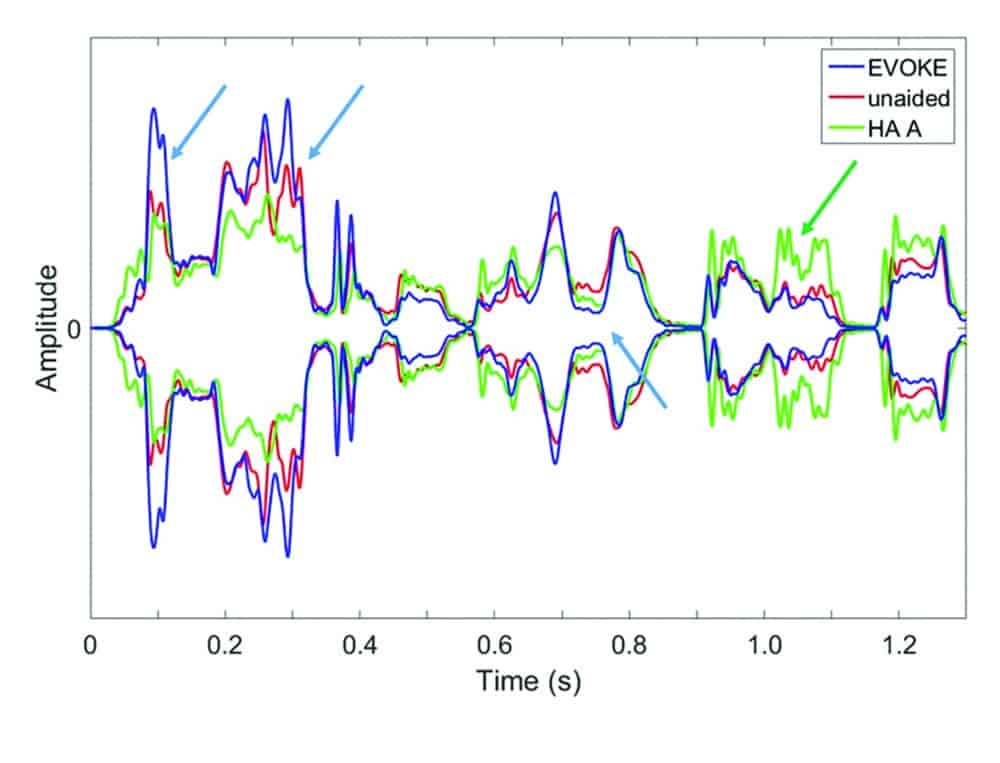
Figure 2. Comparison of the temporal envelopes among the unaided (red curve), EVOKE (blue curve), and HA#A (green curve) with the ISTS signal presented at 80 dB SPL in quiet. The blue and green arrows highlight the difference between the EVOKE, HA# A, and the unaided condition respectively.
When comparing the green curve (HA#A) with the red curve, one sees that the peaks of the green curve stay relatively constant. It is lower than the red curve when the red curve is high (more intense, first 0.2-0.3 s) and higher than the red curve when the red curve is less intense (around 1 s). That is, it keeps a relatively constant peak-to-peak and peak-to-valley difference (see green arrows). This suggests for loud and soft speech, HA#A reduces the temporal envelope dynamics from the unaided condition. Between the two HA conditions, the EVOKE accentuates the temporal envelope dynamics over the unaided condition, while HA#A reduces such differences.
Speech (ISTS) in noise – front. Figure 3 shows the output of the three HA conditions when the speech and noise originate from the same direction. An immediate observation is that the noise floor of the waveform (valleys) has increased over the quiet condition, leading to an envelope with reduced dynamics. A second observation is that both the EVOKE and the HA#A are indistinguishable from the unaided in the “valleys” of the waveform. This suggests that any processing (eg, VSC, noise reduction, or directional microphone) in this test condition (speech and noise front) is not effective in improving the temporal envelope. This is consistent with the current view on noise-reduction algorithms that reduces gain for both speech and noise when a “noise” is detected. On the other hand, at time interval 0.1 – 0.3s, the peaks of the envelope for EVOKE (blue arrow) are higher than that of the unaided and HA#A, while at the 1 s time interval, the peaks of the HA#A are higher than the EVOKE and the unaided condition (green arrow). Thus, one may conclude that on average, neither the EVOKE nor HA#A enhances the unaided temporal envelope.
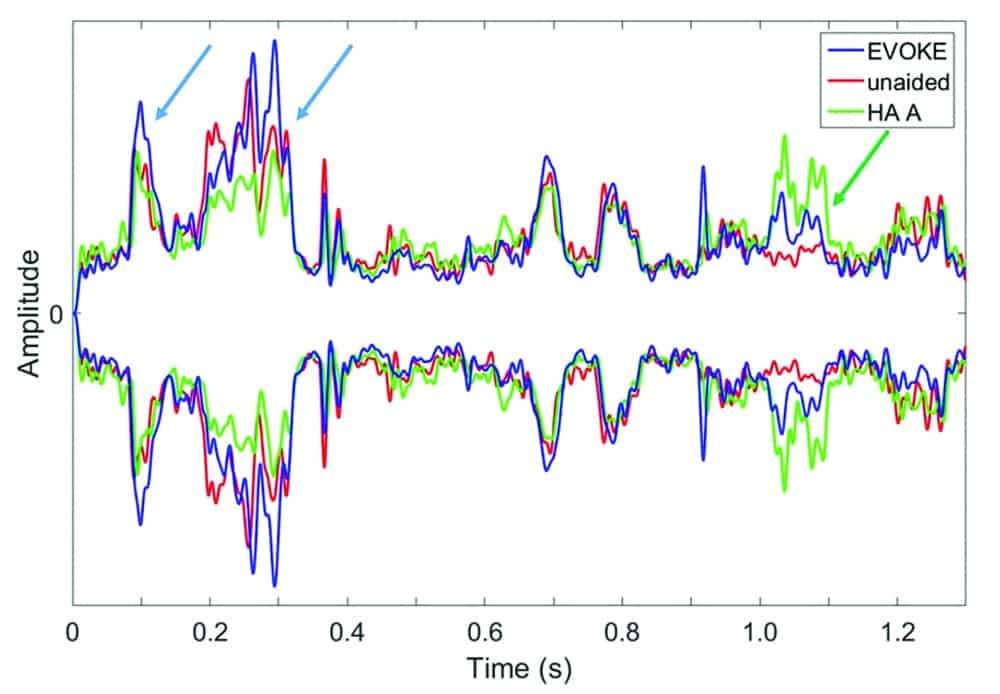
Figure 3. Comparison of the temporal envelopes among the unaided (red curve), EVOKE (blue curve), and HA#A (green curve) with the ISTS signal presented from the front at 80 dB SPL and a continuous noise also presented from the front at a SNR of +10. The blue and green arrows highlight the difference between the EVOKE, HA# A, and the unaided condition respectively.
Speech (ISTS) in noise – back. Figure 4 shows the waveforms when the noise was presented from behind KEMAR. Note that, since both hearing aids have a directional microphone and a noise-reduction algorithm, changes (or lack thereof) in the waveforms would most likely be a consequence of these algorithms, along with the compressor. Several observations are apparent:

Figure 4. Comparison of the temporal envelopes among the unaided (red curve), EVOKE (blue curve), and HA#A (green curve) with the ISTS signal presented from the front at 80 dB SPL and a continuous noise presented from the back at a SNR = +10. The blue and green arrows highlight the difference between the EVOKE, HA#A, and the unaided condition respectively. The red arrows highlight the difference between the unaided and the other two HA conditions during speech pauses.
1) The envelope of the unaided condition is similar to that of the noise presented from the front (see red curve in Figure 3) in that, especially during the pauses, the level of the noise floor is increased. This leads to a reduced temporal envelope.
2) HA#A (green curve) is not much different from the unaided (red curve) in that a relatively similar temporal envelope is seen. The only exception is during pauses of the speech input, where both EVOKE and HA#A show a lower noise floor (than the unaided) and thus an enhanced envelope (red arrows).
3) The EVOKE (blue curve) shows a more enhanced temporal envelope over the red and green curves as evidenced by higher peaks and sometimes lower valleys than the unaided signal (blue arrows). This is likely due to the action of the directional microphone (and perhaps the noise reduction) on the EVOKE.
However, one cannot conclude that all adaptive directional microphones would result in an enhanced temporal envelope, because HA#A also has an adaptive directional microphone and noise reduction algorithm. The fact that the resulting envelope of HA#A is not much different from that of the unaided condition suggests that such algorithms may not be effective or may not have been activated under the specific test conditions. The only region where an enhancement was seen with HA#A at around 1 s (green arrow) was also seen in Figure 2. That enhancement was likely due to the action of the compressor and not from the directional microphone.
Discussion
This investigation demonstrated that the signal processing in the EVOKE results in an accentuated temporal envelope (ie, greater dynamics or contrasts between peaks and valleys) over the unaided condition in both the quiet and noisy backgrounds (with noise from the back). Such observations are not repeatable in HA#A. This highlights the potential differences among commercial devices that have similar frequency response characteristics and advertise similar signal processing features.
It is important to note that the observed difference in temporal envelope among devices does not imply a functional difference in all wearers or all listening conditions. As reviewed above, the functional benefit of a natural or enhanced temporal envelope likely depends on the listener’s reliance on temporal envelope cues. Individuals who do not rely on temporal envelope cues may not experience any benefits from the enhanced envelope cues. Indeed, these individuals may even be able to tolerate a reduced temporal envelope if the fine structure is preserved because of the complementary nature of the fine structure and envelope cues.
On the other hand, individuals who are reliant on temporal envelope cues may benefit more from a natural or enhanced temporal envelope cue. Previous reports suggest greater benefits from slow-acting compression in individuals with poorer cognition,28,29 people with ANSD,20or people with a severe degree of hearing loss.17Because elderly individuals are more likely to confuse vocal emotion,35 preserving the temporal envelope may aid in their detection of vocal emotion.
Thus, it is possible that the amount of enhancement may need to be customized to the temporal processing abilities of the wearers (and their reliance on temporal envelope) in order to optimize benefit. However, there is no reason to suspect that preserving or enhancing these cues will be detrimental to those who may not require them, as long as the fine structures are not compromised. In the future, a means to quantify the temporal envelope change, as well as an index for matching this change to the temporal processing ability of different hearing impaired listeners, may offer new avenues to further improve hearing aid fitting.
References
-
Rosen S. Temporal information in speech: Acoustic, auditory, and linguistic aspects. Philos Trans R Soc Lond B Biol Sci.1992;336(1278):367-373.
-
Luo X, Fu Q-J, Galvin III JJ . Cochlear implants special issue article: Vocal emotion recognition by normal-hearing listeners and cochlear implant users. Trends Amplif. 2007;11(4):301–315.
-
Qin Y, Zhang X. MSF-based speaker automatic emotional recognition in continuous Chinese Mandarin. Procedia Engineering. 2011;15:2229-2233.
-
Moore BCJ. An Introduction to the Psychology of Hearing. 6th ed. Leiden, Netherlands: Brill Publishers;2013.
-
Giraud A-L, Lorenzi C, Ashburner J, et al . Representation of the temporal envelope of sounds in the human brain. J Neurophysiol.2000;84(3):1588–1598.
-
Kubanek J, Brunner P, Gunduz A, Poeppel D, Schalk G. The tracking of speech envelope in the human cortex. PLOS ONE. 2013;8(1):e53398.
-
Moore BCJ. Basic auditory processes involved in the analysis of speech sounds. Philos Trans R Soc Lond B Biol Sci.2008;363(1493):947-963.
-
Moore BCJ. Effects of age and hearing loss on the processing of auditory temporal fine structure. In: Van Dijk P, Ba?kent D, Gaudrain E, de Kleine E, Wagner A, Lanting C, eds. Physiology, Psychoacoustics and Cognition in Normal and Impaired Hearing. 1st ed. Basel, Switzerland: Springer International Publishing;2016.
-
Gordon-Salant S, Yeni-Komshian GH, Fitzgibbons PJ, Barrett J. Age-related differences in identification and discrimination of temporal cues in speech segments. J Acoust Soc Am.2006;119(4):2455-2466.
-
Goupell MJ, Gaskins CR, Shader MJ, Walter EP, Anderson S, Gordon-Salant S. Age-related differences in the processing of temporal envelope and spectral cues in a speech segment. Ear Hear. 2017;38(6):e335-e342.
-
Rawool VW. The effects of hearing loss on temporal processing. Hearing Review.2006;13(6): 42-26.
-
Smith ZM, Delgutte B, Oxenham AJ. Chimaeric sounds reveal dichotomies in auditory perception. Nature. 2002;416:87-90.
-
Liu S, Zeng F-G. Temporal properties in clear speech perception. J Acoust Soc Am.2006;120:424.
-
Krause JC, Braida LD. Acoustic properties of naturally produced clear speech at normal speaking rates. J Acoust Soc Am.2004;115:362.
-
Wang S, Xu L, Mannell R. Relative contributions of temporal envelope and fine structure cues to lexical tone recognition in hearing-impaired listeners. J Assoc Res Oto.2011;12(6):783-794.
-
Van Tasell DJ, Soli SD, Kirby VM, Widin GP. Speech waveform envelope cues for consonant recognition. J Acoust Soc Am. 1998;82:1152.
-
Souza PE, Jenstad LM, Folino R. Using multichannel wide-dynamic range compression in severely hearing-impaired listeners: effects on speech recognition and quality. Ear Hear.2005;26(2):120-131.
-
Wang S, Dong R, Liu D, et al. The role of temporal envelope and fine structure in Mandarin lexical tone perception in auditory neuropathy spectrum disorder. PLOS ONE. 2015;10(6):e0129710.
-
Narne VK, Vanaja CS. Effect of envelope enhancement on speech perception in individuals with auditory neuropathy. Ear Hear.2008;29(1):45-53.
-
Spirakis SE. Auditory neuropathy spectrum disorder and hearing aids: Rethinking fitting strategies. Hearing Review.2011;18(11):28-33.
-
Kuk F, Lau C-C, Korhonen P, Crose B. Evaluating hearing aid processing at high and very high input levels. Hearing Review.2014;21(3):32-35.
-
Oeding K, Valente M. The effect of a high upper input limiting level on word recognition in noise, sound quality preferences, and subjective ratings of real-world performance. J Am Acad Audiol. 2015;26(6):547-562.
-
Chasin M. A hearing aid solution for music. Hearing Review. 2014;21(1):28-31.
-
Plomp R. The negative effect of amplitude compression in multichannel hearing aids in the light of the modulation-transfer function. J Acoust Soc Am. 1998;83:2322.
-
Jenstad LM, Souza PE. Temporal envelope changes of compression and speech rate: Combined effects on recognition for older adults. J Speech Lang Hear Res.2007;50:1123-1138.
-
Kuk FK. Theoretical and practical considerations in compression hearing aids. Trends Amplif. 1996;1(1):5-39.
-
Kuk FK. Rationale and requirements for a slow-acting compression hearing aid. Hear J.1998;51(6):45-53,79.
-
Gatehouse S, Naylor G, Elberling C. Benefits from hearing aids in relation to the interaction between the user and the environment. Int J Audiol.2003;42 (Suppl 1):S77-S85.
-
Lunner T, Sundewall-Thorén E. Interactions between cognition, compression, and listening conditions: Effects on speech-in-noise performance in a two-channel hearing aid. J Am Acad Audiol. 2007;18:604-617.
-
Souza PE, Sirow L. Relating working memory to compression parameters in clinically fit hearing aids. Am J Audiol.2014;23:394-401.
-
Kuk F, Schmidt E, Jessen AH, Sonne M. New technology for effortless hearing: A “Unique” perspective. Hearing Review. 2015;22(11):32.
-
Townend O, Nielsen JB, Balslev D. SoundSense learn–listening intention and machine learning. Hearing Review. 2018;25(6):28-31.
-
Kuk F, Hau O. Compression speed and cognition: A variable speed compressor for all. Hearing Review. 2017;24(3):40-48.
-
Kuk F, Slugocki C, Korhonen P. Better speech-in-noise testing: Demonstration with dual variable speed compression. Hearing Review. 2018;25(8):24-28.
-
Dupuis K, Pichora-Fuller MK. Aging affects identification of vocal emotions in semantically neutral sentences. J Speech Lang Hear Res. 2015;58:1061-1076.

About the Authors:
Francis Kuk, PhD, is the Director; Petri Korhonen, MSc, is Senior Research Scientist, and Christopher
Slugocki, PhD, is a Research Scientist at the Widex Office of Research in Clinical Amplification (ORCA) in Lisle, Ill.
Correspondence can be addressed to Dr Kuk at: [email protected]
Citation for this article: Kuk F, Korhonen P, Slugocki C. Preserving the temporal envelope in hearing aid processed sounds. Hearing Review. 2018;25(10)[Oct]:40-44.