Tech Topic | August 2018 Hearing Review
In recent years, researchers have questioned the validity of the way we compare the outcome efficacy and effectiveness of different signal processing methods.1-3 An important takeaway message is that the test conditions we use in our evaluations may not reflect the real-life listening conditions of the hearing-impaired persons. This implies that the potential benefits we measure in a laboratory/clinical setting may not be seen in the wearers’ daily environments.
How do we assess the speech-in-noise performance of hearing aids in real-life settings to obtain clinically meaningful results? This article looks at several problems related to this issue, including what might constitute “real-life” SNRs and test environments, the variability of patient test scores at different SNRs, and the nonlinearity of modern hearing aids, using the new Widex dual-variable speed compression system as an example.
Such is the case reported in some studies of real-world use of directional microphones.4 This would also suggest that specific signal processing algorithms may not be optimized for real-life use if the assumption of real-life listening conditions made by a manufacturer is different from the real world.5 In this article, we review some of the issues in speech-in-noise (SIN) testing. In particular, we demonstrate the advantage of measuring complete psychometric function at realistic signal-to-noise ratios (SNRs) during SIN testing using the comparison between the dual variable speed compressor (VSC) in the EVOKE hearing aid and a fixed speed compressor as an example.
What Are “Realistic” Listening Conditions?
“Realistic” or “ecologically valid” listening conditions simulate the actual soundscapes (sound pressure levels or SPLs, SNRs, spatial separations, etc) that mimic the real-world listening situations experienced by hearing aid wearers. Clinical speech testing at a conversational level (around 65 dB SPL) is a form of testing under a very specific realistic condition.
On the other hand, hearing aids are often evaluated under test conditions that reflect the design rationale of the specific feature. For example, directional microphones are designed under the assumption that there is spatial separation between speech and noise. To optimally evaluate the efficacy of a directional microphone, laboratory studies are designed so that speech is presented from the front, and background noise is presented from the sides or the back. When the listening conditions deviate from this idealized setting, the advantage of the directional microphone diminishes or vanishes.4Thus, conclusions drawn from laboratory studies are most valid when the test conditions are ecologically valid to the wearer. Real-life conditions that deviate from the test conditions reduce the amount of benefits reported.
Testing in ecologically valid listening conditions requires knowledge of the “realistic” levels and SNRs encountered in daily environments. The study by Pearsons et al6 in 1977 was among the first to examine the real-life speech and SNR levels in various environments. The authors reported that, as the background noise level increases, signal level also increases. In addition, the authors found that typical SNR ranges from -4 dB to 10 dB.
More recently, Smeds et al2 evaluated the SNRs in daily listening environments and reported that realistic SNRs for quiet situations averaged 22 dB, and for different noisy situations ranged between 4.6 and 7.6 dB. Importantly, unlike Pearsons et al,6 the authors found that realistic SNRs rarely fall below 0 dB.
Smeds’ et al’s findings2 were confirmed in a study by Wu et al3 who used an ecological momentary assessment (EMA) technique to study the realistic SNRs of hearing-impaired listeners in their daily environments. These studies define the range of SPLs in different listening environments/situations (like the Pearsons et al research6), and provide a range of SNRs associated with different input levels (like the Smeds et al and Wu et al studies2,3). While daily listening environments can be very noisy, the results of the Smeds et al2 and Wu et al3 studies suggest that hearing-impaired listeners tend to encounter—or are more likely to stay in—listening situations where the SNRs are mostly positive (ie, quiet or not-too-noisy environments between 5 and 15 dB SNR).
Are We Testing Speech in Noise at Realistic SNRs?
An important implication from these studies is that the real-world efficacy of hearing aid signal processing algorithms need to be evaluated with SIN testing in SNR conditions that hearing aid wearers frequently encounter. Currently, there are two ways that clinicians perform SIN testing in the clinic: one is to test at a fixed SNR, and the other is to perform an adaptive SIN test to approximate the SNR for 50% correct speech recognition. There are advantages and disadvantages of each approach; however, a major limitation to both approaches is that performance is only measured at one SNR.
Testing at a fixed SNR. In this approach, speech is presented at one level, and noise is presented at another level from either the same location or a different direction. In either case, the relative levels of the speech and noise are fixed. For example, speech tests (eg, the NU-6) or sentence tests (eg, the Speech Perception in Noise or SPIN test) are typically presented at a fixed SNR.
What does SRT50 mean?
A common outcome of adaptive SIN testing is an index called SRT50. While the SRT50 may be useful in characterizing/profiling an individual patient and for showing the effect of processing, this index may not reflect the degree of listening difficulty in realistic (ie, functionally meaningful) listening situations.
Why not? The SRT50 is the SNR where the person recognizes 50% of what is said; however, he or she still misses 50% of the speech materials. In a real communication situation, one needs to understand much more than 50% of what is said to successfully continue the conversation. Thus, a SRT at a higher criterion, say 85% correct, may be more appropriate than a criterion of 50% if we are looking to evaluate the likelihood of success in daily speech communication. Thus, a person who has an SRT50 at 5 dB and a SRT85 at 10 dB may be able to understand speech at most realistic SNRs, given that Smeds et al2 and Wu et al3 reported that typical SNRs encountered by people with hearing impairment are in this range. On the other hand, a person with a SRT50 at 5 dB but an SRT85 at 15-20 dB may have more difficulty following a conversation in noise at realistic SNRs since the person’s SRT85 is greater than the range typically encountered by hearing-impaired listeners.
Unfortunately, there is little correlation between SRT50 and SRT85 in hearing-impaired listeners, especially for low-context speech materials. At a higher criterion level (ie, SRT85), it is possible that more top-down factors (such as cognition, context, temporal cues, etc) influence the success of speech recognition, whereas success at lower criterion levels (ie, SRT50) may be more determined by bottom-up processing. Of note, it is possible to change the convergence criterion of adaptive SIN tests to different values, such as 75% or 85%, via algorithmic modifications.7
An important consideration when testing at a fixed SNR is to determine what SNR should be used. In a laboratory setting, the SNR should be chosen so as to avoid ceiling and floor effects that may occur when the SNR is too positive or negative. To this end, one may consult the recent work on realistic SNRs. For example, data from Smeds et al2 and Wu et al3 would suggest that SNRs between 5 and 10 dB could be used when speech is at a conversational level. These SNRs would be ecologically valid and the test may reflect performance in daily listening situations.
One drawback to testing at realistic SNRs is that performance for some listeners may reach a ceiling. If the purpose for the SIN testing is to examine “real-life” performance, one may be pleased with the listeners’ performance. On the other hand, if the (or another) purpose for the SIN test is to compare signal processing differences among hearing aids (or hearing-aid features), testing at SNRs that yield ceiling performance may not yield performance differences because they may not be sensitive enough.5
Adaptive speech-in-noise testing. In this approach, either the speech or noise level is adaptively changed based on a preset criterion while the other is fixed at a specific level. By correctly setting the criterion, adaptive testing can avoid performance ceilings/floors.
For example, the Hearing in Noise Test (HINT) fixes the noise level while adaptively changing the speech level; the QuickSin changes the noise level while the speech level is fixed. Both tests converge to find a SNR where sentence recognition or a speech reception threshold (SRT) of 50% correct is reached. However, if the criterion is not set well, the measured SRT may reflect a SNR that does not occur frequently in the wearer’s daily life.
Naylor1 summarized the results of 12 studies that used adaptive tests, and reported SRT50 ranging from -14 to 5 dB SNR—far lower than the typical realistic SNRs reported by Smeds et al2 and Wu et al.3 In other words, adaptive speech in noise testing may not yield an index that provides a realistic appraisal of the person’s SIN ability in real life.
The Problem with Estimating at One SNR or with a Fixed Criterion
Different results at different SNRs. One problem with fixed SNR or adaptive testing is that it only examines one point on the wearer’s “true” speech-in-noise ability curve (or psychometric function). If one is comparing between two hearing aids, this method of testing provides information on only one point (input level) of the hearing aid’s input-output curve. How the individual wearer or hearing aid fares at other SNRs is unknown (see discussion in sidebar, “What does SRT50 mean?”)
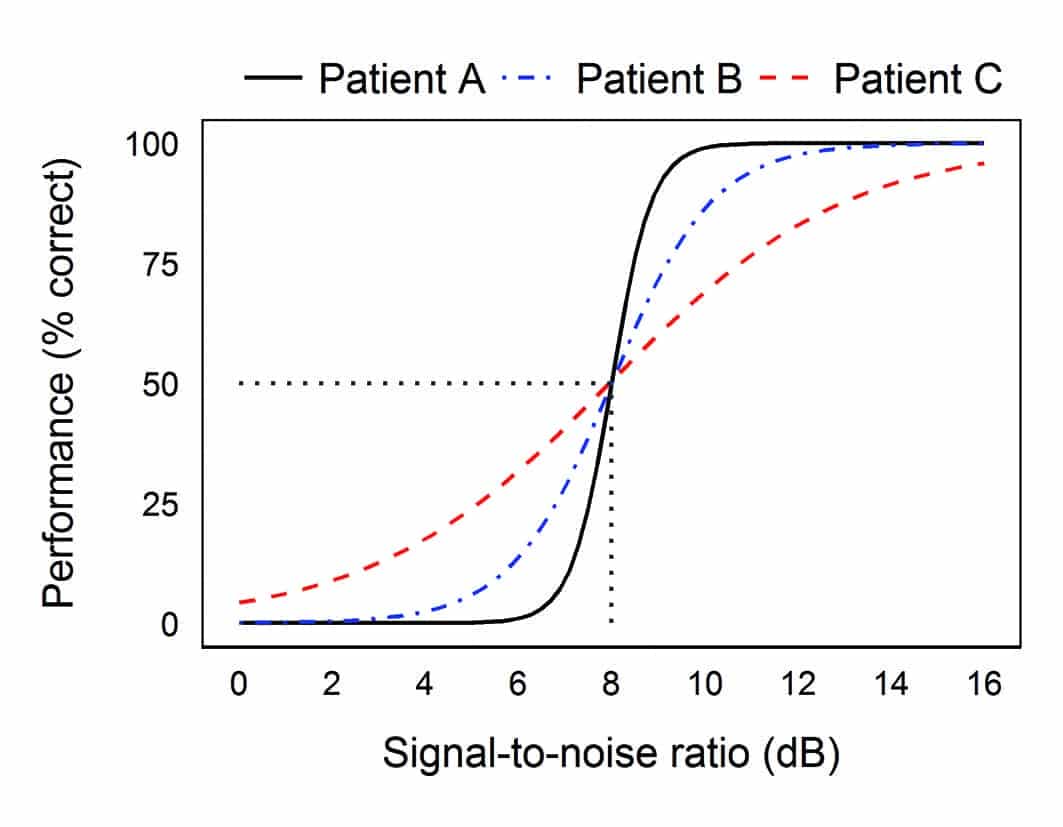
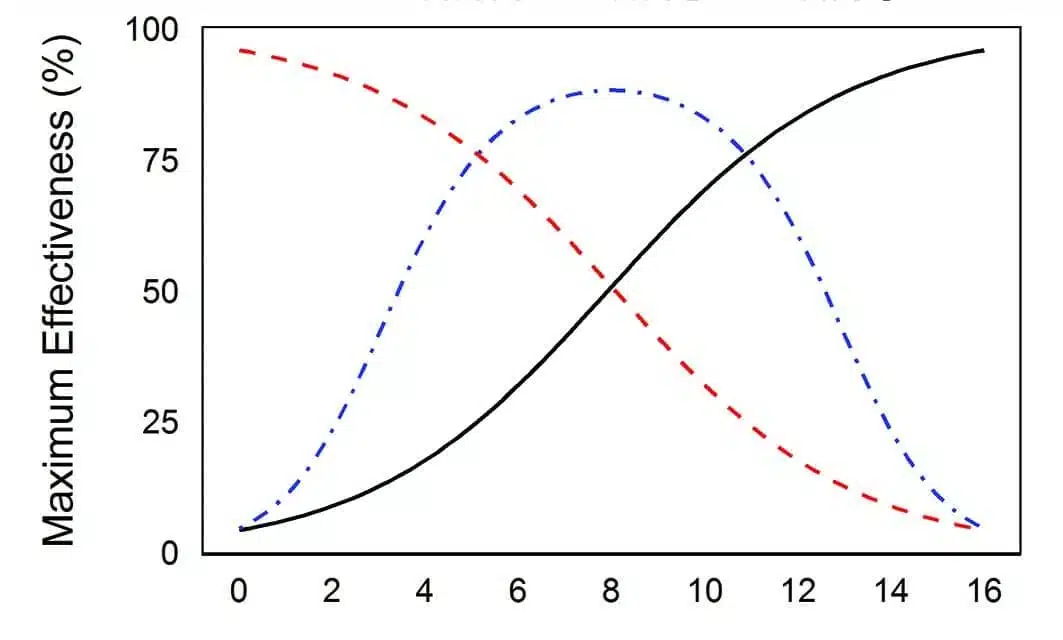
Figure 1. Hypothetical psychometric functions (performance – SNR functions) of three hearing-impaired listeners to the effect of noise.
Figure 1 shows three hypothetical psychometric functions (performance-SNR functions) which all yield a SRT50 at a SNR of 8 dB. Yet if one examines the individual curves, one can see vastly different behaviors in noise. The black curve shows someone who is severely affected by noise below a SNR of 8 dB, but reaches ceiling performance as soon as the SNR is above 8 dB. The red curve shows someone who is affected by noise in a graded manner. Comparing this curve to the black curve, one sees that the red curve outperforms the black curve when the SNR is under 8 dB, but underperforms the black curve when the SNR is above 8 dB. The blue curve represents a person who is “intermediate” between the red and black curves. If these curves were obtained in the unaided mode, technologies that improve the SNR by 6 dB (potentially from a directional microphone) could change the listening environment from a SNR of 4 dB to a SNR of 10 dB. In that case, the performance of the blue and black curve would plateau to around 80%, but the person represented by the red curve would remain at 60%.
Therefore, having information at more than one SNR provides more information about the individual. This allows better counseling for a more realistic expectation and selection of appropriate technologies.
Nonlinearity of hearing aids. Another problem with testing at a single fixed SNR (or SRT criterion) is the inherent nonlinearity of today’s hearing aids. That is, modern hearing aids have nonlinear characteristics so that performance at one SNR may not reflect performance at another SNR.
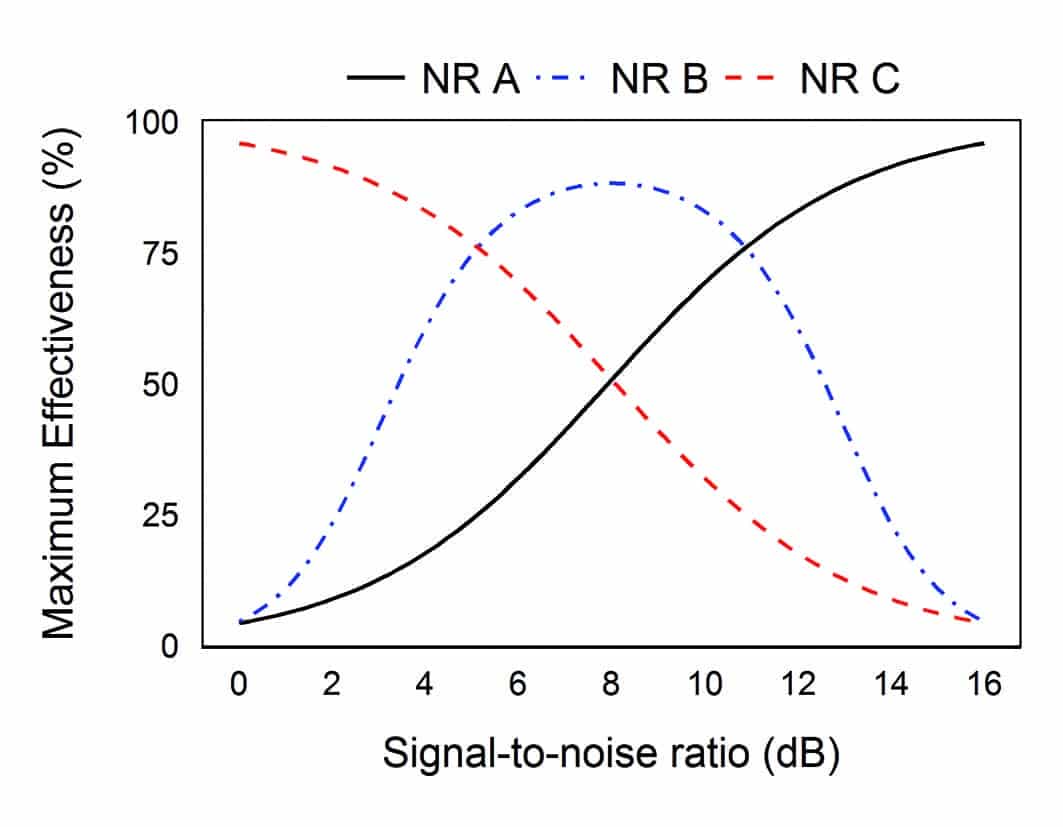
Figure 2. Hypothetical gain reduction vs SNR curves of three hearing aids.
For example, Figure 2 shows the hypothetical gain reduction characteristics of a noise reduction (NR) algorithm from three different hearing aids. The red curve would suggest that this NR algorithm attenuates most at a poorer SNR, the black curve at a most favorable SNR, and the blue curve between 4 and 12 dB SNR. While the red and black algorithms may yield similar gain reduction at a SNR of 8 dB, the behaviors (and thus performance) of all three algorithms at, above, and below this SNR are vastly different. Thus, testing at SNRs that are fixed around 8 dB might lead to the erroneous conclusion that all three algorithms provide similar performance. These kind of differences among hearing aids could result in a noted “benefit” with one hearing aid when it is optimized for the specific test condition (and not other test conditions), but not for another hearing aid that is not optimized for that same condition.
In summary, current methods of SIN testing at a fixed SNR or using adaptive methods that yield a SRT at 50% has the limitation of not fully reflecting the patient’s SIN or the hearing aid’s NR ability over a range of realistic SNRs. Furthermore, a SRT criterion of 50% may not reflect the criterion used by listeners during daily communication. Testing SIN over a range of fixed SNRs that reflect realistic conditions encountered in daily life may be more appropriate. The results of such testing allow one to estimate a listener’s SIN performance across different noise intensities. This paints a more detailed picture of the person’s SIN performance, and allows for an easier and more in-depth comparison of signal processing strategies.
To demonstrate that testing over a range of realistic SNRs (ie, a full psychometric function) may yield more information than testing at one fixed SNR, we examined the difference in speech intelligibility when processed by different compression speeds (dual variable speed compression [VSC], fast-acting compression [FAC], and slow-acting compression [SAC]) on the experimental version of the EVOKE hearing aids.8 The hypothesis is that information from the full psychometric function may be more revealing of the difference among compression speeds than a single index such as the SRT50.
Demonstrating Dual-Speed Compression
The Widex EVOKE hearing aid is built on the dual compressor platform that is used in the Widex UNIQUE and BEYOND product lines (see Kuk et al9 for a detailed description). Briefly, the dual variable speed compressor (VSC) includes a slow compressor (SC) and a fast compressor (FC) that run in parallel in each of the 15 compression channels. The gains from both compressors are added to form the overall gain at each compression channel. We were interested to know the SNR conditions where the VSC design results in a better SIN performance over the use of a single fixed-speed compressor that is either only fast-acting (FAC) or only slow-acting (SAC).
The research version of the EVOKE hearing aid was programmed to each of the three compression speed modes using the hearing loss information of each individual subject. All three compressor modes use the same compression ratios and compression thresholds; they only differ in the time constants (ie, attack and release time) used.
The time constants chosen for the FAC were 5 ms attack and 50 ms release. The time constants chosen for the SAC were 12 ms attack and 3200 ms release. The fast component (FC) of the VSC has an attack time of 12 ms and a release time of 130 ms. The slow component (SC) of the VSC has an attack time of 1500 ms and a release time of 17000 ms. The time constants used in the VSC are those used in the EVOKE hearing aids. In addition, all three compressor modes were set to the same frequency-gain response. This resulted in the same output among compressors when a steady-state pink noise was used to verify output at 50, 65, and 80 dB SPL input levels. A difference in output was noted when a speech stimulus was used to verify output with the FAC having the highest output and the SAC the lowest output (see Figure 3).

Figure 3. Coupler (2cc) output for soft (50 dB SPL), medium (65 dB SPL), and loud (80 dB SPL) input as measured for dual variable speed compressor (VSC), fast-acting compressor (FAC), and slow-acting compressor (SAC) for a pink-noise stimulus (left) and a speech stimulus (right).
Test methods. The Repeat and Recall Test or RRT [submitted paper by Slugocki et al, “Development of an integrated repeat and recall test,” 2018] was used to evaluate speech intelligibility of sentence materials. Each passage of the RRT includes six short sentences, each comprised of 6-8 words. A high context (HC) and a low context (LC) version of the test are available for evaluating the use of contextual cues in speech understanding.
A total of 17 adult hearing-impaired experienced listeners (12 females, 5 males) with a bilaterally symmetrical mild-to-moderate sloping hearing loss participated. They ranged from 33 to 83 years in age (mean = 65.5 yrs, SD =14.6). All were native English speakers. All listeners were tested with the three compressor modes (VSC, FAC, and SAC) in a counterbalanced order. A double-blind design was used. For each hearing-aid condition, RRT passages were presented at 75 dB SPL in quiet and at a fixed SNR from 0 to 15 dB in 5 dB increments. The order of the SNR conditions was randomized for each participant. The low-context version of the RRT was presented first, followed by the high-context sentences. Testing at all SNRs was completed with one compressor mode before another compressor mode was initiated.
Results
Figure 4 shows the Repeat performance intensity (P-I) function for the HC and LC versions of the RRT. For both sets of materials, it is evident that performance increases as SNR increases. Both plateau at around a SNR of 10 dB; however, HC materials reach a plateau of around 96%, while the LC materials plateau around 90%.
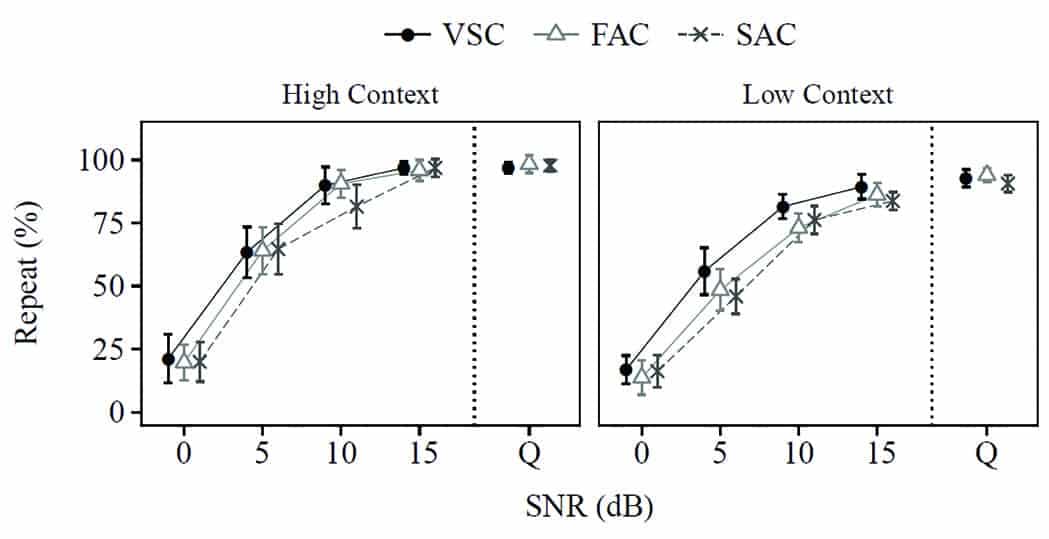
Figure 4. Comparison of VSC (bold dots), FAC (triangles), and SAC (Xs) on mean listener repeat performance measured with the ORCA-RRT. Stimuli were presented at SNR = 0, +5, +10, and +15 dB and in Quiet (Q). Results are shown for all listeners for high context (left) and low (right) context passages. Error bars represent 95% confidence intervals of the mean (within-subjects adjusted).
For the HC materials, performance was similar among compressor types. For the LC materials, VSC trended higher than FAC and SAC, while SAC did not differ from FAC. A mixed-design ANOVA was used to assess the within-subject factors of compressor speed (VSC/FAC/SAC), test condition (0/5/10/15 dB SNR or Quiet), and passage context (HC/LC) on the Repeat RRT measure. As expected, RRT outcome measures were significantly affected by the SNR of the test condition (F(4,56) = 545.71, p< 0.001, ?2 = 0.80) and by passage context (F(1,14) = 116.45, p< 0.001, ?2 = 0.13).
We fit logistic functions to the P-I curves using performance at SNR = 0, 5, 10, and 15 dB and estimated the speech reception thresholds at a 50% correct criterion (SRT50) and at 85% correct criterion (SRT85). Sentence scores for HC and LC sentences were combined for the measurement because passage context did not interact significantly with compressor type. At a criterion of 50% (ie, SRT50), SRT for VSC was 4.8 dB, FAC was 5.1 dB, and SAC was 5.2 dB. The slight difference was not statistically significant (F(2,28) = 1.11, p= 0.34).
On the other hand, at a criterion of 85% (SRT85), VSC was 9.6 dB, FAC was 11 dB, and SAC was 11.4 dB. SRT85was significantly lower (better) for VSC compared to FAC (t(15) = -2.46, p< 0.05) and SAC (t(15) = -2.44, p< 0.05). This suggests that VSC is significantly better than FAC and SAC at some SNRs using a realistic criterion. There was no difference between FAC and SAC (t(15) = -0.70, p= 0.50). Figure 5 summarizes the SRT50and SRT85for the various compressor speeds.

Figure 5. Effect of compressor speed on average Speech Reception Thresholds (SRTs) at 50% (left) and 85% (right) correct criteria (SRT50 and SRT85; dB SNR) across all listeners for VSC (bold dots), FAC (triangles), and SAC (Xs). Compressor effect shows the average of HC and LC passages. Error bars represent 95% confidence intervals. Asterisks over bars denote significant contrasts.
Discussion
The potential benefits of measuring the complete psychometric function, as evidenced from the study with the EVOKE hearing aid, are that:
1) It offers a more complete understanding of the wearer’s SIN performance, and
2) It offers a means to differentiate among technologies (in this case compression speeds) where a traditional approach (ie, SRT50) may not reveal a significant difference.
A more complete description of wearer’s SIN ability. Wu et al,3 based on their study of realistic SNR using EMA technique, reported that wearers classified their listening situations with a SNR ranging from 0 to 5 dB as “noisy” or “very noisy.” Situations with SNRs ranging from 5 to 10 dB were rated as “somewhat noisy,” while situations with SNRs ranging from 10 to 15 dB (and above) were rated as “quiet.” Using these criteria, one can see from Figure 4 that the average subject in this study recognizes between 20% and 60% of the sentences in “noisy” and “very noisy” situations, 40% to 80% in a “somewhat noisy” situation, and 80% to 100% in a “quiet” situation. This means that the SIN problem that a hearing-impaired person reports is not fixed, but varies depending on the SNR of the listening environments and the content and context of the conversation. This information would be useful for counseling purposes and would be easier for the hearing-impaired clients to understand than informing them that they have “a SNR loss of X dB.”
An additional avenue to differentiate among technologies. Traditionally, we measure the SRT at a 50% criterion as a means to test for speech intelligibility differences among technologies. In this study with the EVOKE, we observed that the slight difference between VSC and FAC/SAC at SNRs that corresponds to 50% correct was not statistically significant.
On the other hand, a statistically significant difference of 1.4 dB and 2 dB was noted between VSC vs FAC and VSC vs SAC, respectively. This means that while one may not observe a difference among compressor speeds at a SNR that corresponds to 50% correct—which is classified as a “noisy” to “somewhat noisy” realistic listening situation—there is a noted difference among compressor speeds at a SNR that corresponds to 85% correct or “somewhat noisy” to “quiet” situations.
Considering that the typical realistic SNR reported by Smeds et al2 and Wu et al3 are at around 10 dB, this observation of a difference among compressor speeds suggests that the average hearing aid wearer would experience the difference among compressor speeds in their daily environments. In other words, for realistic SNRs, the VSC may have better optimization than FAC and SAC. Simply measuring the SRT at a 50% criterion, as one traditionally does, would have missed this difference.
The concept of examining performance differences at SNRs that correspond to a higher performance criterion (ie, between 80% and 90% correct) is not new. Lunner and Sundewall-Thorén10examined differences between fast and slow compression, and reported the greatest difference between cognitive groups at SNRs that corresponded to an 80% performance level. Additionally, Lunner et al11 examined the efficacy of a noise reduction algorithm on the Sentence Final Word Identification and Recall Test in a New Language (SWIRL)12 at SNRs corresponding to 95% correct. The results of this study support those observations, suggesting that it is beneficial to examine differences in signal processing at SNRs where the performance is high, but not at ceiling.
In summary, we recommend to clinicians who are interested in measuring speech in noise to do so by measuring the full psychometric function, at minimum, across 3 to 4 realistic SNRs (eg, 5 to 15 dB SNR). The results of such measurements would yield a more complete picture of the hearing-impaired person’s SIN ability. It may also be a more sensitive means to differentiate among technologies as evidenced in this recent EVOKE hearing aid study on the efficacy of VSC compression over a fixed speed (FAC and SAC) compression.

Biography: Francis Kuk, PhD, is the Director, Christopher Slugocki, PhD, is a Research Scientist, and Petri Korhonen, MSc, is Senior Research Scientist at the Widex Office of Research in Clinical Amplification (ORCA) in Lisle, Ill.
CORRESPONDENCE can be addressed to Dr Kuk at: fkuk@widex.com
Citation for this article: Kuk F, Slugocki C, Korhonen P. Better speech-in-noise testing: Demonstration with dual variable speed compression. Hearing Review. 2018;25(8):24-28.
References
-
Naylor G. Theoretical issues of validity in the measurement of aided speech reception threshold in noise for comparing nonlinear hearing aid systems. J Am Acad Audiol. 2016;27(7): 504-514.
-
Smeds K, Wolters F, Rung M. Estimation of signal-to-noise ratios in realistic sound scenarios. J Am Acad Audiol. 2015;26(2):183-196.
-
Wu Y-H, Stangl E, Chipara O, Hasan SS, Welhaven A, Oleson J. Characteristics of real-world signal to noise ratios and speech listening situations of older adults with mild to moderate hearing loss. Ear Hear.2018; 39(2)[March/April]:293-304.
-
Walden B, Surr R, Cord M. Real world performance of directional microphone hearing aids. Hear Jour.2003;56(11):40-47.
-
Smeds K, Wolters F. Towards a firm grip on auditory reality. Hearing Review.2017;24(12): 20-25. Available at: https://hearingreview.com/2017/11/towards-firm-grip-auditory-reality
-
Pearsons KS, Bennett RL, Fidell S. US Environmental Protection Agency. https://nepis.epa.gov/Exe/ZyNET.exe/P100CWGS.TXT?ZyActionD=ZyDocument&Client=EPA&Index=1976+Thru+1980&Docs=&Query=&Time=&EndTime=&SearchMethod=1&TocRestrict=n&Toc=&TocEntry=&QField=&QFieldYear=&QFieldMonth=&QFieldDay=&IntQFieldOp=0&ExtQFieldOp=0&XmlQuery=&File=D%3A%5Czyfiles%5CIndex%20Data%5C76thru80%5CTxt%5C00000021%5CP100CWGS.txt&User=ANONYMOUS&Password=anonymous&SortMethod=h%7C&MaximumDocuments=1&FuzzyDegree=0&ImageQuality=r75g8/r75g8/x150y150g16/i425&Display=hpfr&DefSeekPage=x&SearchBack=ZyActionL&Back=ZyActionS&BackDesc=Results%20page&MaximumPages=1&ZyEntry=1&SeekPage=x&ZyPURL Speech levels in various noise environments. Published 1977.
-
Keidser G, Dillon H, Meija J, Nguyen C-V. An algorithm that administers adaptive speech-in-noise testing to a specified reliability at selectable points on the psychometric function. Int J Audiol.2013;52(11):795-800.
-
Kuk F, Hau O. Compression speed and cognition: A variable speed compressor for all. Hearing Review.2017;24(3): 40-48. Available at: https://hearingreview.com/2017/03/compression-speed-cognition-variable-speed-compressor
-
Kuk F, Slugocki C, Korhonen P, Seper E, Hau, O. Evaluation of the efficacy of a dual variable-speed compressor over a single fixed speed compressor. J Am Acad Audiol. 2018;In press.
-
Lunner T, Sundewall-Thorén E. Interactions between cognition, compression, and listening conditions: Effects on speech-in-noise performance in a two-channel hearing aid. J Am Acad Audiol.2007;18(7):604-617.
-
Lunner T, Rudner M, Rosenbom T, Ågren J, Ng EHN. Using speech recall in hearing aid fitting and outcome evaluation under ecological test conditions. Ear Hear.2016;37[Suppl 1]: 145S–154S.
-
Ng EHN, Rudner M, Lunner T, Rönnberg J. Noise reduction improves memory for target language speech in competing native but not foreign language speech. Ear Hear.2015;36(1):82-91.