
Research | December 2018 Hearing Review
A new test that assesses speech-in-noise performance and verbal working memory
A broader appreciation for the unique difficulties faced by many of our patients relative to speech understanding in noise and working memory is critical to tailoring individualized interventions that help them realize the full potential of their residual hearing. At present, the Repeat and Recall Test (RRT) shows promise as an efficient, audiology-based integrative tool of speech-in-noise assessment that includes a more complete understanding of a listener’s experience in a loud speech background at various realistic SNRs.
Speech understanding is a highly complex learned behavior. Successful communication relies not only on the integrity of the sensory signal at the periphery, but also on the listeners’ pre-existing lexical repertoires and on their cognitive abilities. It makes sense then that speech understanding varies not only as a function of hearing loss, but also as a function of the listener’s age and the complexity of the listening task.
Unsurprisingly, such variation persists even after corrective amplification. Better profiling patients to reveal the issues underlying their speech understanding difficulties would certainly be useful to clinicians. However, such comprehensive assessment is beyond the scope of any single existing speech test.1
Common speech tests tend to focus on limited parts of the speech processing chain. Many tests ask the listener to repeat phonemes (eg, ORCA-NST 2), monosyllabic words (eg, NU-6 3), or simple sentences (eg, CST 4) as heard in varying levels of background noise. Of course, recognizing the simple units of speech does not predicate the success of real-life communication. Rather, success in everyday conversation requires continuous speech processing throughout and between speech segments.
The result is that most speech tests ignore the many cognitive factors involved in natural language processing. This reflects a practical trade-off, where clinical efficiency comes at the cost of ecological relevance. Finding a way to incorporate the cognitive element into clinical assessments should be especially relevant to hearing care professionals because a significant portion of the population that we serve are older adults and many experience varying degrees of age-related declines in cognitive function.
Considerations Behind an Integrated Test
For the sake of face validity, an audiology-centric cognitive assessment should target factors that are strongly associated with language processing. In this regard, working memory (WM) assessments are promising because individual differences in WM are thought to underlie part of the variability in listeners’ speech-in-noise understanding.5 In general, WM refers to the collection of cognitive resources that individuals use to encode, store, and process information.6 During communication, WM is involved in the retrieval and maintenance of speech information in a way that facilitates the extraction of meaning. Often, this also involves inhibiting irrelevant information, such as competing talkers, nearby sounding words, or background noise.7
The WM proficiency of an individual is typically quantified by their working memory capacity (WMC), which refers to the number of informational units the individual is able to store and process simultaneously. It is known that WMC often (but not always) declines as part of the normal aging process.8 Thus, listeners with good WM may be able to allocate resources to processing degraded speech with ease and still have spare capacity remaining for storage or memory. Conversely, listeners with poor WM may need to engage all of their cognitive capacity to process speech-in-noise, which makes listening feel very effortful.
Although tests of verbal WM exist (eg, Reading/Listening Span Test 9), they are tedious for the patient and ask too much time of the administering clinician. There are faster tests of WM, such as the digit span test10 or the N-back test,11 but these may not engage the same kinds of processing used during verbal communication.
A single test that assesses speech-in-noise performance and verbal WMC is desirable for both clinical efficiency and face validity. As a first step, Pichora-Fuller et al12 adapted the SPIN-R test to measure WMC by introducing a delayed recall task for sentence-final words. More recently, Smith et al13 developed the Word Auditory Recognition and Recall Measure (WARRM) that assesses recognition and recall for speech materials presented in quiet at relatively loud levels (70 to 80 dB HL).
Although the SPIN-R and WARRM are good examples of integrated speech recognition and WM tests, they assess listener performance in optimal but not necessarily “realistic” conditions. This is important because, if a test is to predict real-life performance, then it should reasonably approximate the listening conditions of everyday communication. A more realistic test might use semantically meaningful sentence-level speech materials, and score recognition and recall for different types of mono- and multisyllabic words at different positions in the sentence. Sentence-level speech materials can also provide means to evaluate how well listeners use semantic contextual cues to aid with speech recognition, which may be further revealing of cognitive deficits.14
There are likely differences in how hearing-impaired listeners deploy their cognitive resources when communicating in different listening environments. When listening conditions or task demands become challenging, listeners may shift from a processing mode that is relatively effortless and/or automatic to one that is more effortful and/or attention-driven. Research has shown that real-life communication occurs over a range of mostly positive signal-to-noise ratios (SNRs), and rarely does communication continue if the SNR is below 0 dB.15,16 This makes sense because listeners are not likely to tolerate a communication condition that has little chance of success; instead, they may choose to move to improved listening conditions.
The point to which speech understanding can be degraded before listeners disengage with listening likely varies from listener to listener. These judgements are probably based on the listener’s perceived understanding of the message, on the effort required to hear that message, and on her/his internal motivation to engage with the messenger.5 Accessing the subjective quality of communication difficulties could help to reveal subtle differences between listeners in how they cope in listening conditions where speech-understanding performance is otherwise equal. Such perception may be estimated through judgment of listening effort17 and usage time.18
For these reasons, a clinical assessment that considers how listeners’ cognitive abilities interact with the perceived effort and motivation to communicate in noisy situations may serve as an efficient tool with which to better understand and counsel the patient’s particular real-life speech difficulties.5
Developing the Integrated Repeat and Recall Test (RRT)
Following these considerations, Widex ORCA-US developed the Repeat and Recall Test (RRT). The RRT integrates a sentence-level speech recognition task (ie, repeat) with an auditory WM task (ie, recall). During the repeat phase, listeners are asked to repeat each of six sentences after they are heard and to commit these sentences to memory. The test administrator scores predefined target words for correct repetition. After repeating all six sentences, listeners are asked to recall (in any order) as much content from the sentences that they just heard. Only those target words that were repeated correctly during the repeat phase are eligible for scoring during the recall phase.
After recall, listeners rate how effortful they found the listening situation on a 10-point rating scale, with “1” representing minimal effort, “5” representing moderate effort, and “10” representing very effortful listening. Finally, listeners provide an estimate of how much time (in minutes) they would be willing to spend listening to the talker under the specific test conditions. Administration of the RRT is fully guided by software, and requires less than 2 minutes for any single SNR condition.
Speech materials used in the RRT test are grouped into five sets, where each set is thematically related to one of five topics: Food & Cooking, Books & Movies, Music, Shopping, and Sports. Each set includes seven passages, each of which includes six syntactically correct and semantically meaningful sentences related to the set’s topic. These constitute the “high context” (HC) version of the test. Each sentence contains 3 or 4 target words (mostly nouns, adjectives, and verbs) so that 20 target words are scored for every passage. All sentences are targeted at a fourth-grade reading level as measured by the Flesch-Kincaid reading level scale.
Unique to the RRT, each passage has a complementary “low-context” (LC) version, where target words are rearranged within the passage of six sentences to create sentences that are syntactically correct but meaningless (see Figure 1 for an example of the RRT speech materials). This design allows for comparison of listener performance between high- and low-context passages while controlling for acoustical differences or factors pertaining to target word difficulty. In this way, clinicians can measure how listeners use contextual cues to help with their speech recognition.

Figure 1. An overview of the RRT speech corpus. The test evaluates performance on complementary high- and low-context passages related to one of 5 topics. There are 7 different passages available per topic. An example of high- and low-context sentences taken from Passage 1 of the Food & Cooking set is shown on the right. Words that have been bolded in yellow represent targets that are eligible for scoring during the repeat and recall components of the test. Note how target words are conserved between complementary high- and low-context passages.
The RRT is administered in quiet and in noisy conditions over a range of fixed SNRs (eg, -5 to +15 dB) that are typical of real life listening situations.15,16 The order of the test conditions is randomized for each listener. To minimize any carryover effects from semantically meaningful sentences, testing always begins with the LC versions of any particular sentence set. Speech materials are presented as audio recordings of a native Midwestern male talker that have been filtered to have a long-term average spectrum of “loud” speech. A two-talker babble is used as the noise stimulus. During testing, speech stimuli are presented at 75 dB SPL-C. The level of the babble noise is then adjusted to produce the desired SNR for a given test condition. Both speech and noise are presented from the same loudspeaker positioned at 1 m directly in front of the listener (ie, 0° azimuth).
Validating the RRT
Participants. To validate the RRT, we administered the test to a sample of 20 normal-hearing (mean age = 50.1, SD = 15.6 years) and 16 hearing-impaired adult listeners (mean age = 64.1, SD = 15.2 years). All participants were native speakers of American English recruited from the local community. Normal-hearing listeners had four-frequency pure-tone averages (PTAs) less than 20 dB up to 2 kHz, and less than 30 dB HL above 4 kHz. Hearing-impaired listeners had PTAs of 48.7 (±11.5 SD) and 50.0 dB HL (±12.8 SD) for right and left ears, respectively (Figure 2). All participants passed the Montreal Cognitive Assessment (MoCA)19 for general cognitive function. Participants were informed of the purpose of the study and the potential risks and benefits, before giving their written consent to participate. Participants were compensated financially.
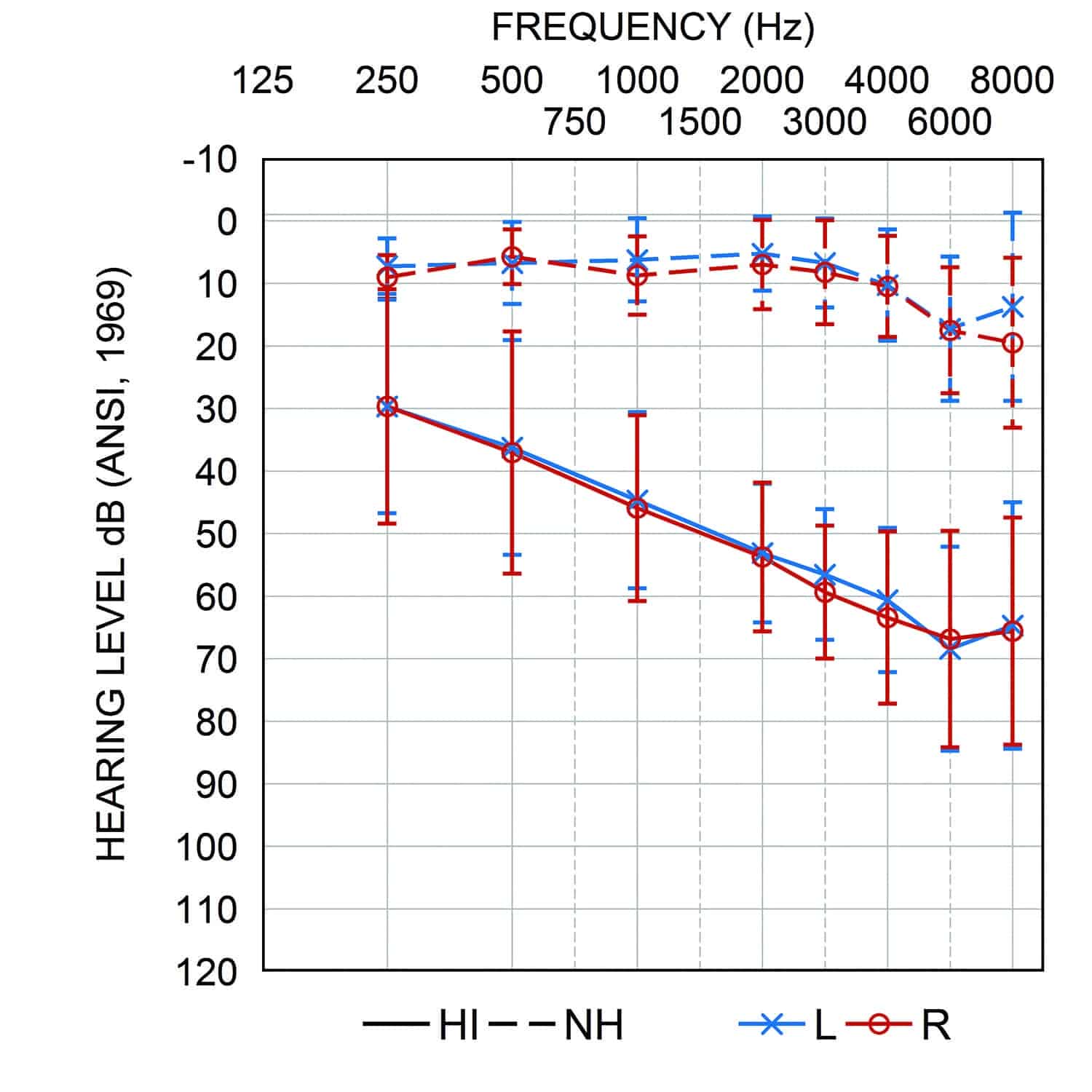
Figure 2. Average audiograms of hearing-impaired (solid lines) and normal hearing listeners (dashed lines) tested in the current study. Error bars represent ±1 SD of the mean.
Procedure. Normal hearing listener performance for all speech materials (ie, all 5 topics) in quiet and at fixed SNRs, ranging from -5 to +15 dB in 5 dB steps, were measured over the course of two visits. During a third visit, listener performance was reassessed using speech materials from Visit 1 in order to determine test-retest reliability.
Hearing-impaired listener performance was assessed over the course of two visits using the same procedure described for normal hearing listeners, with two exceptions. First, the -5 dB SNR condition was eliminated because of its difficulty. Second, listener performance was assessed using only the shopping and sports sentence sets. These sets were chosen because they had been used to assess normal-hearing listeners on Visits 1 and 3. Thus, comparison of normal hearing and hearing-impaired performance across these lists would be the least confounded by differences in sentence set difficulty and/or practice with the task. Additional tests of speech-in-noise recognition (ie, HINT 20) and verbal WMC (ie, RST 21) were administered to all listeners in order to assess the external validity of the RRT performance metrics. All participants were tested in a sound-treated booth with speech and noise presented from the same front loudspeaker. Normal hearing listeners were tested in the unaided mode; hearing-impaired listeners were tested in the aided omnidirectional mode with all adaptive features deactivated.
Evaluating the equivalence of speech materials in normal hearing listeners. To avoid possible confounds related to audibility, the equivalence of the RRT’s speech materials was evaluated solely on the performance of normal hearing listeners. Overall, we found that repeat and recall performance was within 10% (or 2 words) across sentence sets (Figure 3). Mixed-design analyses of variance (ANOVAs) found that the Sports sentence set was the most difficult to repeat (p < 0.05) and the Food & Cooking sentence set was the easiest to recall (p < 0.01). The remaining three sentence sets were statistically similar in both the repeat and recall performances. Ratings of listening effort and tolerable time did not vary significantly between sentence sets (p > 0.05). This suggests that the Shopping, Books & Movies, and Music sets can be used interchangeably to compare listener performance across different conditions (eg, different hearing aid settings). On the other hand, when testing with either the Food & Cooking or the Sports sentence sets, comparisons should be limited to speech materials from within a set to avoid introducing potential errors related to differences in sentence set difficulty.
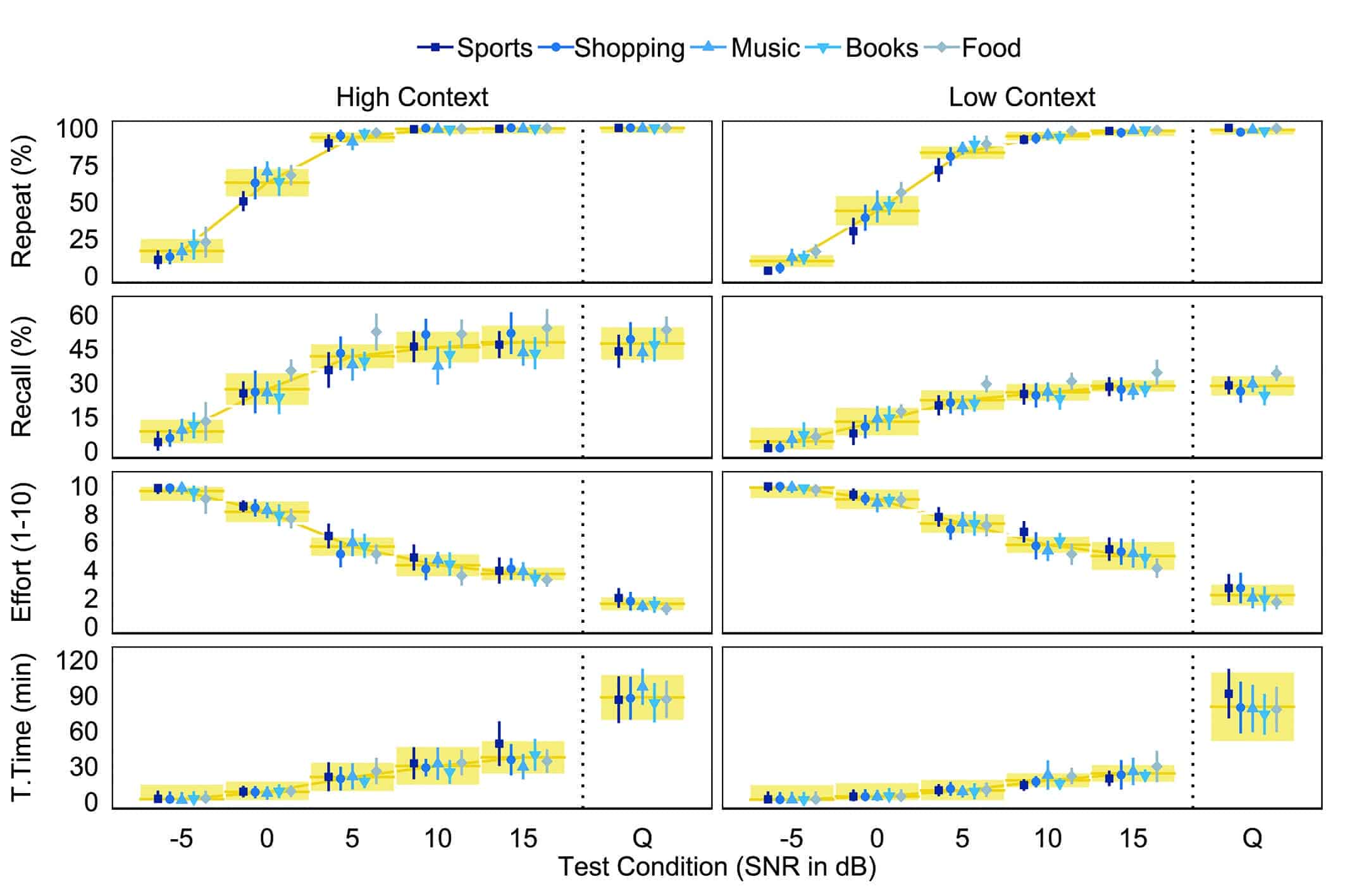
Figure 3. Performance intensity functions for repeat, recall, listening effort, and tolerable time scores in normal hearing listeners. Data are shown for high-context (left panels) and low-context (right panels) passages as presented in babble noise at -5, 0, +5, +10, and +15 dB SNR as well as in quiet (Q). Average listener performance is represented for each of the 5 sentence set topics (blue symbols). Shaded areas (yellow) at each test condition represent ±1 SD of the mean (solid yellow line) of all participants across all 5 sentence sets.
Comparing normal hearing and hearing-impaired listener performance. Average performance intensity functions of normal hearing and hearing-impaired listeners are shown in Figure 4. Mixed design analyses of covariance (ANCOVAs) were used to assess whether listener group (ie, normal hearing versus hearing-impaired) had any effect on each RRT outcome measure. The ANCOVAs also assessed any possible effect of passage context and controlled for listener age as a covariate. Assessment of repeat performance was limited to estimates of SRT-50, slopes, and performance plateaus derived from psychometric functions fit to each listener’s data. Assessment of recall, listening effort, and tolerable time was limited to scores measured in quiet and in noise conditions spanning the steepest portion of the repeat and recall PI functions of hearing-impaired listeners (ie, 0, +5, and +10 dB SNR). Hence, analyses involving these latter outcome measures also included the possible effect of noise.
Repeat performance (Figure 4a) on the RRT decreased as a function of SNR in both groups. As expected of a speech-in-noise measure, average estimates of SRT-50 were significantly higher (p < 0.05) for hearing-impaired listeners (HC = 1.7 dB ±2.6 SD, LC = 3.3 dB ±2.7 SD) compared to normal-hearing listeners (HC = -1.1 dB ±1.6 SD, LC = 1.3 dB ±1.8 SD), indicating poorer performance. Estimates of SRT-50 were also significantly higher for LC compared to HC passages in both groups (p < 0.001). Further analysis found that hearing-impaired listeners plateaued at a significantly lower repeat score (mean = 89% ±7.9 SD) than did normal hearing listeners (mean = 96.9% ±3.5 SD) when tested with LC passages (p < 0.01). The slopes of repeat performance functions were not affected by listener group or passage context (p > 0.05).
Recall performance (Figure 4b), ratings of listening effort (Figure 4c), and reports of tolerable time (Figure 4d) were each significantly affected by the interaction of listener group, passage context, and noise. In both normal hearing and hearing-impaired listeners, recall performance was greater for HC than for LC passages (p < 0.001), and in quiet than in noise (p < 0.001). Similar effects of passage context and noise were observed for reports of tolerable time (both, p < 0.001) and ratings of listening effort (both, p < 0.001), where the direction of the effects was reversed for listening effort. Post hoc analyses showed that recall performance was significantly better for hearing-impaired compared to normal hearing listeners when tested with HC passages in quiet (p < 0.05). Hearing-impaired listeners also found HC passages less effortful than LC passages in quiet (p < 0.001) and reported longer tolerable time for HC than for LC passages in quiet (p < 0.01), whereas no such differences were observed in the normal hearing group.
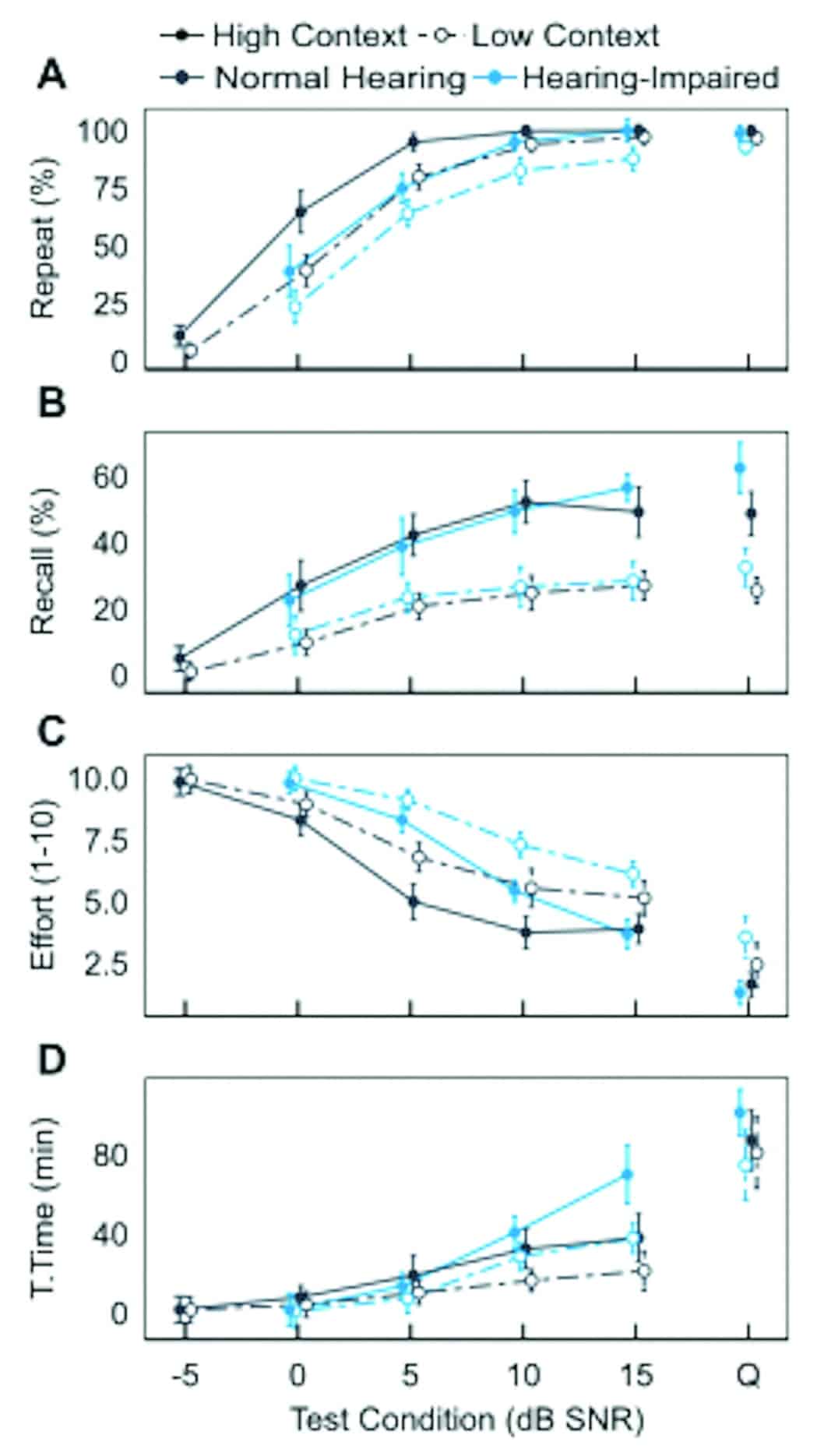
Figure 4. Performance intensity functions for A) repeat, B) recall, C) listening effort, and D) tolerable time scores in normal hearing (dark blue) and hearing-impaired (light blue) listeners. Data are shown for high context (solid lines, filled circles) and low context (dashed lines, open circles) passages as presented in babble noise at -5, 0, +5, +10, and +15 dB SNR as well as in quiet (Q). Error bars represent 95% confidence intervals of the sample mean.
External validity and test-retest reliability. Across all listeners, repeat performance was found to correlate with listeners’ HINT scores (partial r = 0.40, p < 0.05) and recall performance correlated with RST scores (partial r = 0.53, p < 0.01), after accounting for listener age and hearing status. Moreover, assessment of intraclass correlation coefficients (ICC) suggests that a single administration of the RRT produces reliable estimates of repeat (ICC = 0.83) and recall performance (ICC = 0.75). Together, these results demonstrate that the integrated RRT produces valid measures of speech-in-noise performance and verbal WM in older adults.
Discussion
The current study demonstrates that a single administration of the RRT, which lasts less than 20 minutes, produces valid metrics of a listener’s objective performance (ie, repeat and recall) and subjective perception (ie, listening effort and tolerable time) across different ecologically valid listening conditions.
RRT as a valid measure of WM. The strength of the association between listeners’ auditory-based RRT recall and their reading-based RST scores (partial r = 0.45-0.52) was similar to that reported in other studies comparing reading- and listening-based assessments of WMC in younger (19-35 years old, r = 0.49-0.60)22and middle-aged (40–70 years old, r = 0.67)23 normal hearing adults. Pichora-Fuller et al12 also found reading (RST) and auditory (recall-adapted SPIN-R) WM spans to be correlated in normal hearing younger (r = 0.56) and older (r = 0.71) adults. We interpret this to mean that the RRT engages similar WM processes as those engaged in other WM tests. This suggests that the recall component of the RRT is a promising auditory-based measure of WMC and may be used to assess a patient’s WMC in the clinic. It is important to reiterate that WMC is not an indicator of mild cognitive impairment (MCI) or dementia. However, understanding how sensorineural hearing loss and WMC contribute to speech-in-noise deficits can be useful in developing individualized counseling strategies and improving the overall hearing health of patients.
The role of context in speech-in-noise processing. The availability of contextual cues interacted differently with SNR to affect speech-in-noise performance in hearing-impaired and normal hearing listeners. At highly positive SNRs, aided speech recognition of hearing-impaired listeners matched that of the normal hearing group with HC sentences. Context also improved the hearing-impaired listeners’ recall ability to outperform the normal hearing group. The effect we observed cannot be attributed to general cognitive differences between our two subject groups because they did not differ in RST or MoCA scores. The difference may be a result of continued reliance on contextual cues by the hearing-impaired listeners such that it evolves into efficient rehearsal strategies that are not used by normal hearing listeners. The better recall of HC materials at high positive SNRs was associated with lower ratings of listening effort and reports of longer tolerable time.
Pichora-Fuller et al12 suggests that contextual cues can shift the burden of processing from perceptually driven to cognitively driven mechanisms. This process can result in positive feedback, where cognition improves speech identification, which then provides additional context cues to further help with understanding speech-in-noise. Consistent with this idea, not only was performance better for high (versus low) context passages, but the slopes of the repeat PI functions were also steeper for high context passages (mean = 8.4% dB ±4.7 SD) than for low context passages (mean = 7.6% dB ±3.7 SD).
Arguably, one advantage of using the RRT over the RST is its sensitivity to the role of context in natural language processing. Research has shown that both semantic and syntactic cues are utilized by listeners to “chunk” sentence materials for enhanced memory storage and retrieval, over that measured for lists of words or digits.24 The recall component of the RRT acknowledges that chunking strategies are likely used in daily communication, and awards listeners for recall of predefined target words at 3-4 positions within each sentence. The RRT might be useful in quantifying the degree to which individual listeners use semantic cues to retain speech content at different SNR conditions.
Whether such information may guide fitting remains a topic for future investigation. However, our results demonstrate that a speech test that goes beyond speech recognition performance can indeed reveal interesting differences in how hearing-impaired listeners encode speech information and how they experience communication situations at realistic positive SNRs.
Possible Clinical Applications of the RRT
The current preliminary study provides insight into performance differences on the various RRT measures between normal and hearing-impaired listeners with normal cognitive function. Ideally, the performance of any clinical patient could be compared to that reported in this study to determine whether that patient falls within the normal range. For example, a listener may show normal performance on the repeat scale, but poorer-than-normal recall performance and greater listening effort. This could suggest additional cognitive resources may be needed to achieve satisfactory repeat performance. Alternatively, a listener with normal repeat performance, but significantly less-than-normal self-reported tolerable time, might indicate an inherent dislike of communication in noisy situations. This potential application of the RRT would need to be validated as we gain more experience with the test.
Future standardization of the RRT will require a larger sample of listeners that covers a wider range of cognitive abilities, hearing losses, and age groups. Readers who are interested to contribute to the normative sample are urged to contact the authors for a copy of the software and instructions to administer the test most efficiently. Nonetheless, at present, the RRT shows promise as an efficient, audiology-based integrative tool of speech-in-noise assessment that includes a more complete understanding of a listener’s experience in a loud speech background at various realistic SNRs. A broader appreciation for the unique difficulties faced by many of our patients is critical to tailoring individualized interventions that help patients realize the full potential of their residual hearing.
CORRESPONDENCE can be addressed to HR or Dr Slugocki at: [email protected]

About the Authors: Christopher Slugocki, PhD, is a Research Scientist, Francis Kuk, PhD, is the Director, and Petri Korhonen, MSc, is Senior Research Scientist at the Widex Office of Research in Clinical Amplification (ORCA) in Lisle, Ill.
Citation for this article: Slugocki C, Kuk F, Korhonen P. Development and clinical applications of the ORCA Repeat and Recall Test (RRT). Hearing Review. 2018;25(12)[Dec]:22-26.
References
-
Pichora-Fuller MK. Audition and cognition: what audiologists need to know about listening. Paper presented at: Hearing Care for Adults: An International Conference; November 2006; Chicago, Ill. https://www.audiologyonline.com/releases/phonak-announces-proceedings-from-their-4129.
-
Kuk F, Lau C-C, Korhonen P, Crose B, Peeters H, Keenan D. Development of the ORCA Nonsense Syllable Test. Ear Hear. 2010;31(6):779-795.
-
Tillman TW, Carhart R. An expanded test for speech discrimination utilizing CNC monosyllabic words: Northwestern University Auditory Test No. 6. https://apps.dtic.mil/dtic/tr/fulltext/u2/639638.pdf. USAF School of Aerospace Medicine Aerospace Medical Division technical report SAM-TR-66-55. Published June 1966.
-
Cox RM, Alexander GC, Gilmore C. Development of the Connected Speech Test (CST). Ear Hear.1987;8[Supp 5]:119S–126S.
-
Pichora-Fuller MK, Kramer SE, Eckert MA, et al. Hearing impairment and cognitive energy: The framework for understanding effortful listening (FUEL). Ear Hear.2016;37:5S–27S.
-
Baddeley AD, Hitch G. Working memory. In: Bower GH, ed. The Psychology of Learning and Motivation: Advances in Research and Theory.Vol 8. New York, NY: Academic Press;1974:47-89.
-
Gordon-Salant S, Cole SS. Effects of age and working memory capacity on speech recognition performance in noise among listeners with normal hearing. Ear Hear.2016;37(5):593-602.
-
Hedden T, Gabrieli JDE. Insights into the ageing mind: A view from cognitive neuroscience. Nat Rev Neurosci. 2004;5:87-96.
-
Daneman M, Carpenter PA. Individual differences in working memory and reading. J Verbal Learning Verbal Behav. 1980;19(4):450-466.
-
Koppitz EM. The Visual Aural Digit Span Test. Bloomington, MN: Pearson Clinical;1977.
-
Kirchner WK. Age differences in short-term retention of rapidly changing information. J Exp Psychol.1958;55(4):352-358.
-
Pichora-Fuller MK, Schneider BA, Daneman M. How young and old adults listen to and remember speech in noise. J Acoust Soc Am.1995;97(1):593-608.
-
Smith SL, Pichora-Fuller MK, Alexander G. Development of the Word Auditory Recognition and Recall Measure: A working memory test for use in rehabilitative audiology. Ear Hear.2016;37(6):e360-e376.
-
Kalikow DN, Stevens KN, Elliott EE. Development of a test of speech intelligibility in noise using sentence materials with controlled word predictability. J Acoust Soc Am. 1977;61(5):1337-1351.
-
Smeds K, Wolters F, Rung M. Estimation of signal-to-noise ratios in realistic sound scenarios. J Am Acad Audiol. 2015;26(2):183-196.
-
Yu-Hsiang W, Stangl E, Zhang X, Perkins J, Eilers E. Psychometric functions of dual-task paradigms for measuring listening effort. Ear Hear. 2016;37(6):660-670.
-
McGarrigle R, Munro KJ, Dawes P, et al. Listening effort and fatigue: What exactly are we measuring? A British Society of Audiology Cognition in Hearing Special Interest Group ‘white paper.’ Int J Audiol. 2014;53(7):433-445.
-
Cox RM, Alexander GC, Beyer CM. Norms for the International Outcome Inventory for Hearing Aids. J Acad Audiol.2003;14(8):403-413.
-
Nasreddine ZS, Phillips NA, Bédirian V, et al. The Montreal Cognitive Assessment, MoCA: A brief screening tool for mild cognitive impairment. J Am Geriatr Soc.2005;53(4):695-699.
-
Nilsson M, Soli SD, Sullivan JA. Development of the Hearing in Noise Test for the measurement of speech reception thresholds in quiet and in noise. J Acoust Soc Am. 1994;95(2):1085.
-
Van den Noort M, Bosch P, Haverkort M, Hugdahl K. A standard computerized version of the Reading Span Test in different languages. Eur J Psychol Assess.2008;24:35-42.
-
Besser J, Koelewijn T, Zekveld AA, Kramer SE, Festen JM. How linguistic closure and verbal working memory relate to speech understanding in noise—A review. Trends Amplif. 2013;17(2), 75-93.
-
Koelewijn T, Zekveld AA, Festen JM, Rönnberg J, Kramer SE. Processing load induced by informational masking is related to linguistic abilities. Int J Otolaryngol.2012;Article 865731:1-11.
-
Marks LE, Miller GA. The role of semantic and syntactic constraints in the memorization of English sentences. J Verbal Learning Verbal Behav.1964;3(1):1-5.



![Out of the [Head] Shadow: A Systematic Review of CROS/BiCROS Literature](https://hearingreview.com/wp-content/uploads/2021/06/sound_waves_in_ear-440x264.jpg)
Thank you for this research
I am very interested in incorporating this testing in my clinic. Please send me more information.
JGW