A New Fitting Algorithm for Maximizing Acceptance of Hearing Instruments
XCEL-Fit is Siemens’ newest fitting algorithm, which is designed to maximize spontaneous acceptance and long-term satisfaction. This is achieved by incorporating a unique combination of fitting flexibility and psychoacoustic models for both effective audibility as well as sound quality. This article details the rationale behind XCEL-Fit and presents three studies that suggest XCEL-Fit provides the audibility comparable to a state-of-the-art fitting algorithm, such as NAL or DSL, and is the preferred fitting formula when compared with other premium products.
When patients come to the hearing care professional with the general interest in obtaining hearing aids, they usually are seeking to “hear better.” And what they typically mean by better hearing is improved audibility. As hearing care professionals, however, we know that when we provide what would be considered “appropriate audibility,” many new users often find amplified sounds from hearing instruments annoyingly loud or having an unacceptable sound quality. In other words, the goals of restoring audibility—yet maintaining excellent sound quality—are not always supportive of each other.
We also know that the first few weeks of hearing instrument use are critical to the patient’s overall success in using amplification. That is, new users often can become discouraged if this initial hearing aid experience does not meet expectations. A patient who has an initial “poor experience” may not try hearing aids again for several years.
To maximize spontaneous acceptance of amplification, therefore, improved audibility must be carefully balanced with sound quality. To do this, we have to consider the individual listening preferences and preferred loudness levels for each patient.
Some patients prefer to have more audibility, while others have a higher preference for sound quality. These preferences are based on a variety of factors including the patient’s hearing loss, loudness growth function, typical listening situations, and lifestyle.
Historically, we have used validated prescriptive fitting methods as a starting point for programming hearing aids. In general, these methods tend to focus on optimizing intelligibility, which directly relates to providing appropriate audibility. One prescriptive formula in common use today is DSL v5.0 from the National Centre for Audiology at the University of Western Ontario. While several modifications have occurred, the general goal of DSL over the years has been “loudness normalization.” In other words, its focus is on audibility.1,2 The other commonly used prescriptive method is from the National Acoustics Laboratory (NAL) in Australia, with the most recent modification being NAL-NL2. NL2 utilizes a speech intelligibility model that takes some individual characteristics into account,3 but the primary emphasis of NAL-NL2 is speech intelligibility (audibility), not sound quality.
However, experience has shown that, for some patients, the gain prescribed by traditional formulas tends to be considered too loud or too shrill—especially by first-time users. This is not conducive to optimal spontaneous acceptance, which is so essential for patients’ ultimate success with hearing instruments.
Balancing Audibility, Comfort, and Sound Quality—from the Start
To ensure the optimal balance of audibility and listening comfort, Siemens XCEL-Fit was developed. XCEL-Fit is the default fitting formula for Siemens Pure XCEL, Motion XCEL SX, Motion XCEL P, and Eclipse XCEL Hearing Instruments. This prescriptive algorithm employs psychoacoustic models of both speech intelligibility and sound quality. The starting point for XCEL-Fit is NAL-NL2. However, unlike NAL-NL2, which is heavily weighted toward maximizing speech intelligibility, XCEL-Fit has a different theoretical base that promotes spontaneous acceptance by carefully balancing audibility and sound quality.
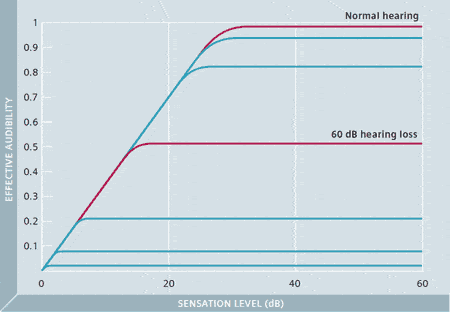
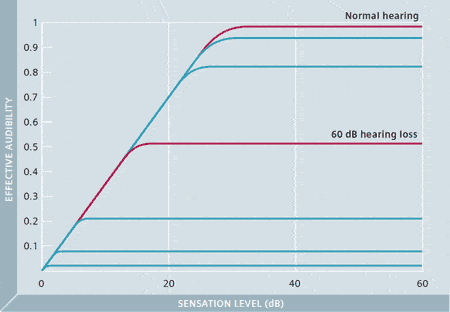
Figure 1. Research by Ching and colleagues4 shows that effective audibility decreases as hearing loss increases. Any amplification beyond effective audibility does not significantly contribute to speech intelligibility.
To optimize audibility, XCEL-Fit employs the psychoacoustic model for effective audibility. Effective audibility predicts the amount of audibility that contributes to individual speech intelligibility based on average hearing loss values.4 The concept of effective audibility has research roots at the NAL and has been incorporated into the NAL-NL2 prescriptive fitting algorithm. Their studies have shown that the effective audibility for a normal-hearing individual is about 30 dB. This means that as the level of speech increases from 0 dB SL (sensation level), the normal hearing listener’s speech intelligibility increases accordingly. When the level reaches approximately 30 dB SL, the speech intelligibility usually attains full 100% (Figure 1, red curve; for normal-hearing individuals).
If the speech signal exceeds 30 dB SL, speech intelligibility will not improve any further. This concept of effective audibility also holds true for hearing-impaired listeners. The SL required for effective audibility, however, decreases with increasing hearing loss. For example, for a 60 dB HL hearing loss, the effective audibility is only about 20 dB (with some differentiation as a function of frequency) (Figure 1, second red curve). For this hearing loss, the maximum speech intelligibility will be reached at approximately 20 dB SL. Even though in some cases this maximum speech intelligibility might only be about 50%, increasing the loudness further would exceed effective audibility and therefore not improve speech intelligibility any further. This means, for those with hearing loss, providing gain past effective audibility may only compromise sound quality without contributing to speech intelligibility. In XCEL-Fit, we actively use the concept of effective audibility to generate gain targets that eliminate unnecessary gain that could reduce sound quality.
To arrive at a fitting formula that optimizes spontaneous acceptance, we need to use not only a psychoacoustic model for speech intelligibility and loudness, but also a psychoacoustic model for optimal sound quality. The Siemens proprietary model for sound quality is derived primarily from two other psychoacoustic models: the Speech Intelligibility Index (SII)5 and the Model of Comfort for Hearing Impaired-Speech (MCHI-S).6 The SII takes into consideration the distribution of speech energy across the frequencies to estimate speech intelligibility based on a particular hearing loss. The MCHI-S, on the other hand, estimates the perception of loudness, sharpness, and overall sound quality based on the hearing loss. By combining the results from these two models, the Siemens psychoacoustic model for sound quality is able to ensure fittings that provide an excellent sound quality without undermining speech intelligibility.
While the theory behind Siemens XCEL- Fit is sound, it is important to conduct empirical research to determine the effectiveness of this new algorithm. Three different studies were conducted to examine how this fitting strategy compared to other fitting methods regarding speech understanding and users’ sound quality impressions.
Study I: Speech Recognition and Comfort in Noise
As mentioned, one of the goals of the new XCEL-Fit is to maintain speech intelligibility, while providing improved listening comfort. Therefore, our first research effort, conducted at a university research site, was to determine if speech recognition was maintained when hearing aids were programmed to this algorithm.7 A total of 22 adults with downward sloping hearing losses (all new hearing aid users fitted bilaterally) served as study participants. The Siemens Motion 701 BTE instruments were programmed to two different fitting strategies: XCEL-Fit and the NAL-NL2. All features (eg, directionality, digital noise reduction, etc) were set the same for both fittings.
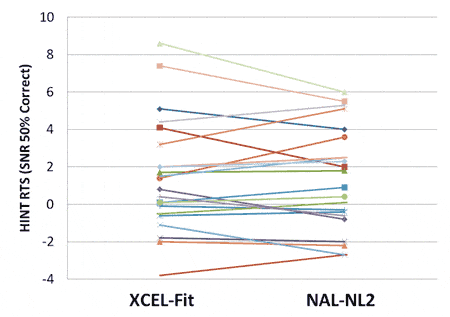
Figure 2. Distribution of the HINT RTS scores for 22 subjects when fitted with the XCEL-Fit and the NAL-NL2 prescriptive algorithms.
Speech-in-noise testing was conducted using the Hearing in Noise Test (HINT). Both the speech and noise were presented from a loudspeaker located 1 meter from the participant at 0° azimuth. The noise was delivered at 65 dB SPL; the speech signal (20 sentences) was adaptively altered to obtain the SRT-in-noise (50% correct for sentences). Testing was conducted for both algorithms, with test order counterbalanced.
The results of the speech testing are shown in Figure 2. The distribution for the 22 subjects is similar for both fitting algorithms. If we consider the critical difference for the HINT to be 2 dB, only two subjects showed this degree of difference, one favoring the NAL-NL2 and the other favoring XCEL. Most importantly, there was no significant mean differences between the performance for the two fitting methods (p<.001), with mean HINT RTS values of 1.4 dB for both strategies.
These findings demonstrate that, when individuals are fitted using the XCEL algorithm, speech understanding remains equal to a recognized prescriptive fitting method such as the NAL-NL2.
Study II: Speech Recognition and Sound Quality Benchmarks
In a second study to determine the effectiveness of this new fitting formula, XCEL-Fit was evaluated in a clinical study against another premium hearing instrument. This benchmark study was carried out at the Hearing Center at Oldenburg (Germany) with 15 subjects who were fit binaurally with the Siemens Pure 701 XCEL S and the other hearing instrument in a cross-over experiment. The average audiogram of the participants is shown in Figure 3.
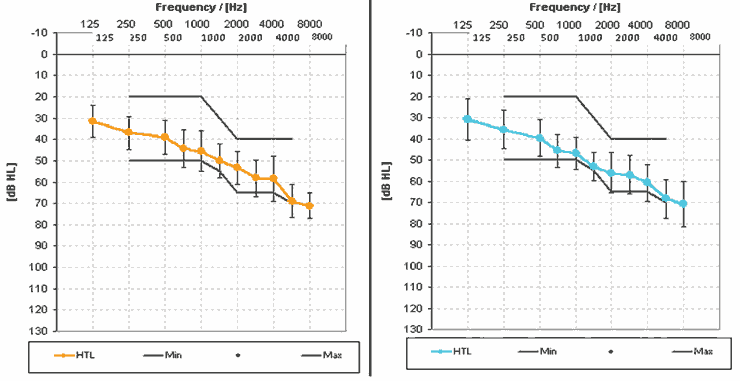
Figure 3. Average hearing loss and the range of losses for the right and left ears for 15 subjects.
The clinical evaluation consisted of an objective and a subjective task, both involving speech material. For the speech recognition evaluation, the Oldenburg Sentence Test was used. This is an adaptive nonsense sentence test where the background noise level was presented at a fixed level of 65 dB SPL and the presentation level of the sentences was adapted to arrive at a speech reception threshold (SRT) in noise. The speech was presented from a loudspeaker located 1 meter away at a 0° azimuth and the noise at 135° azimuth.
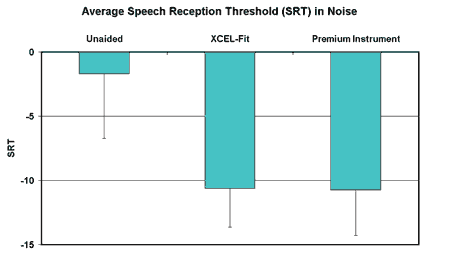
Figure 4. Benchmark study results of XCEL-Fit versus a premium instrument. Speech reception threshold results in noise show that in terms of speech intelligibility, significant improvement is noted from unaided, and that XCEL is comparable to the other premium instrument.
For the sound quality portion of the evaluation, the subjects were asked to rate the two hearing instruments on a 4-point scale ranging from “very dissatisfactory” to “very satisfactory” for sound quality. For this task, the subjects were presented sound samples of speech in quiet, speech in noise, and music in a sound-treated booth. Following this testing, a brief interview with the investigator also was conducted at which time the participants selected their overall preference.
As can be seen from Figures 4 and 5, XCEL-Fit performs comparably with the other instrument in terms of preserving speech recognition, even in the presence of background noise. The similarity between the two instruments changes, however, for sound quality, where XCEL provides better sound quality. This improvement is observed for sound quality overall, as well as for speech in quiet conditions, and also in terms of own voice. The participants reported the most improvement for the perceived sound quality of music.
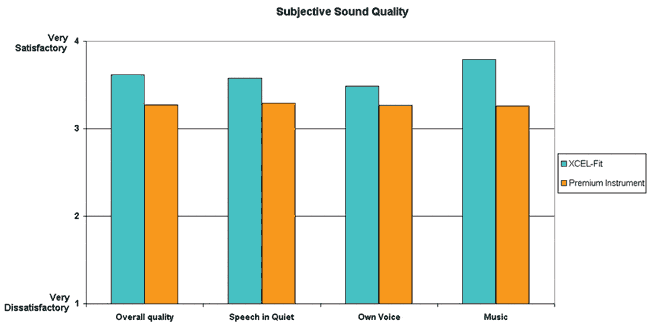
Figure 5. Average of the participants’ ratings for aspects related to sound quality. Note that in general, ratings are higher for XCEL-Fit (ratings are for a 4 point scale with 1=very dissatisfactory and 4=very satisfactory).
Study III: Paired Comparisons Versus Two Premium Devices
In a third study, conducted with 15 experienced subjects with similar hearing losses as used in Study II, XCEL-Fit was evaluated against two premium instruments in a paired-comparison paradigm. In this research, the subjects listened to XCEL-Fit, as well as the other premium products, fitted to the default First Fit of their respective manufacturers. The participants selected the fitting algorithm that provided the best speech understanding, the fitting that sounded the most natural, as well as their overall preferred fitting. Using the forced-choice paired-comparison paradigm, each “fitting” was paired against the other two fittings 27 times for the 15 subjects, resulting in a total of 405 comparisons for each product (Figure 6).
In general, the results of this study revealed that, when compared against other premium instrument fitting algorithms, XCEL-Fit is considered the preferred algorithm for subjective speech understanding, natural sound quality, as well as the overall preferred algorithm.
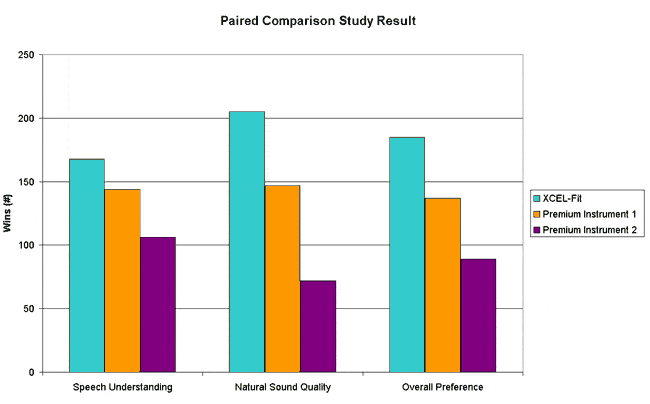
Figure 6. Preferred fitting algorithm for subjective speech understanding, sound quality, and overall preference in a paired comparison study.
Summary
To maximize spontaneous acceptance of hearing instruments, fitting algorithms need to focus not only on audibility and speech intelligibility, but also on sound quality. Siemens XCEL-Fit incorporates psychoacoustic models for effective audibility as well as for sound quality in order to maximize spontaneous acceptance.
Three clinical studies were conducted to evaluate XCEL-Fit:
- Study 1 shows that the new algorithm is comparable to NAL-NL2 in terms of speech intelligibility.
- Study 2 shows that, when compared with a widely dispensed premium instrument, XCEL-Fit offers similar speech intelligibility, but superior sound quality.
- In Study 3, a comparison study against two premium instruments, XCEL-Fit was shown to be the formula that offers the best subjective speech understanding, sound quality, as well as the overall preferred algorithm.
References
- Scollie S, Seewald R, Cornelisse L, Moodie S, Bagatto M. The Desired Sensation Level multistage input/output algorithm. Trends Amplif. 2009;9(4):159-197.
- Seewald R, Moodie S, Scollie S, Bagatto M. The DSL method for pediatric hearing instrument fitting: historical perspectives and current issues. Trends Amplif. 2005;9(4):145-157.
- Keidser G, Dillon H. The NAL-NL2 prescription; background, derivation, and how it differs from NAL-NL1. Audiology Online Webinar. May 2009.
- Ching TY, Dillon H, Byrne D. Speech recognition of hearing-impaired listeners: predictions from audibility and the limited role of high-frequency amplification. J Acoust Soc Am. 1998;103(2):1128-40.
- American National Standards Institute (ANSI). Methods for Calculation of the Speech Intelligibility Index (No. S3.5 – 1997). 1997.
- Goenner L, Haubold J. Speech intelligibility prediction for normal hearing and hearing impaired subjects—MCH-S. Paper presented at: NAG/DAGA International Conference on Acoustics; March 23-26, 2009; Rotterdam.
- Weber J, Byrnes S, Coppinger S, Erdruegger D. Clinical Evaluation of a New Hearing Aid Fitting Algorithm [doctoral project]. Greeley, Colo: University of Northern Colorado; 2012.
Citation for this article:
Herbig R, Berghorn K, Fischer R-L, Weber JE, Powers T, and Kindt M. A New Fitting Algorithm for Maximizing Acceptance of Hearing Instruments. Hearing Review. 2012;19(08):30-41.



