
Back to Basics | February 2014 Hearing Review
By Marshall Chasin, AuD
Modern hearing aid technology has the capability to be responsive to varying levels of inputs. A hearing aid will generate significant amplification for soft level inputs, less amplification for medium level inputs, and sometimes no amplification for louder level inputs. Many people simply do not need a lot of hearing aid amplification for the louder components of speech (and music). Many hard-of-hearing people may say, “I can hear fine if people would only speak up a bit,” and they are quite correct. Understandably, there has been a significant amount of research in this area for speech, but very little for music.
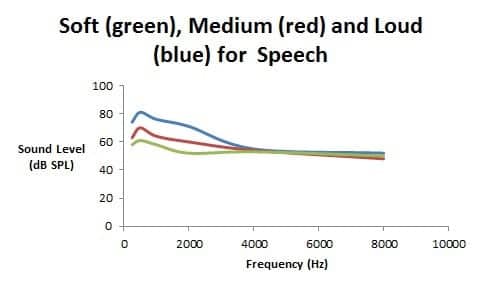
Figure 1.Spectra for soft (green), medium (red), and loud (blue) speech in dB SP
Figure 1 shows a sample of one person’s speech spectrum for three speaking levels. As can be seen, as a person speaks at a higher level, it is primarily the lower frequency vowels and nasals (ie, the sonorants) that increase in level whereas the higher frequency consonants (eg, s, f, th, sh) are only slightly louder—one simply cannot utter a loud “th” as one can utter a loud “a” sound.
Music is an entirely different type of input to hearing aids. Where speech can be soft (55 dB SPL), medium (65 dB SPL), or loud (80 dB SPL), especially for the lower frequency region, music can be soft (65 dB SPL), medium (80 dB SPL), or loud (95 dB SPL). Music tends to be shifted up one “loudness” category as compared with speech. There are other “statistical” differences between speech and music that involve the crest factor and other temporal features; however, a major difference is that music is louder than speech.
So far, this seems rather straightforward: for a music program, adjust “quiet” music to be like medium speech; adjust “medium” music to be like loud speech; and adjust “loud” music to be like very loud speech—perhaps subtract 5-10 dB from the amplification for a music program for loud music than what would be programmed for loud speech.

Figure 2.Spectra (in dB SPL) for soft, medium, and loud playing levels for reeded instruments such as clarinets and saxophone.
Now it gets a little bit tricky. Can we definitively say that music has well-defined features for soft, medium, and loud levels? Figures 2 and 3 show the spectra for soft, medium, and loud music. Figure 2 is for reeded instruments (eg, clarinet, saxophone, oboe, and bassoon), and Figure 3 is for stringed and brass instruments (eg, violin and trumpet). As can be seen, music has different properties as the playing level gets louder, and these can be grouped into reeded instruments and “the rest.”

Figure 3. Spectra (in dB SPL) for soft, medium, and loud playing levels for stringed and brass musical instruments.
With reeded instruments, as one blows harder to create a louder sound, the reed distorts, thereby providing more high frequency harmonic energy with almost no increase in the lower frequency fundamental (the note name) energy. In contrast, for stringed and brass instruments, when playing louder, it’s rather straightforward: the volume for all frequencies is turned up similarly with a maintenance of the spectral shape.
As is found with many proprietary hearing aid fitting software programs, with speech, for louder inputs, one can prescribe less low- and mid-frequency gain than for softer speech. The high frequency gain should be left pretty much the same for all speaking levels. For clarinet and saxophone music, for loud playing levels, the higher frequency gain can be reduced relative to softer playing levels. And for the stringed and brass instruments, there can be gain reduction for all frequency regions as the playing level increases.
Marshall Chasin, AuD, is an audiologist and director of research at the Musicians’ Clinics of Canada, Toronto. He has authored five books, including Hearing Loss in Musicians, The CIC Handbook, and Noise Control—A Primer, and serves on the editorial advisory board of HR. Dr Chasin has guest-edited two special editions of HR on music and hearing loss (March 2006 and February 2009), the latter with Larry Revit, as well as a special edition on hearing conservation (March 2008) with Lee Hager.
Original citation for this article: What is “soft,” “medium,” and “loud” for speech and music? Hearing Review. 2014: February: 12.


