The SRT has little bearing on overall word recognition ability. Although there appears to be a working assumption or approach in our field (and even within the research community) for using the 50% data point to predict maximum speech processing performance, this is, in fact, an effort without any clinical or theoretical foundation.
Is it feasible to use the Speech Recognition Threshold (SRT) as a predictive measure of an individual’s Word Recognition Score (WRS)? During the course of the hearing aid selection process, a decision needs to be made between two hearing aids or between the performance settings on a single hearing aid. One performance setting yields a SRT that is better than the other. What major factors behind a clinical decision weigh into the equation among today’s dispensing professionals? When viewing a device being able to provide a better SRT at a lower signal presentation level or at a better signal-to-noise ratio (SNR, or S/N ratio) as compared to other devices, what should the professional expect from a device that has a better SRT? Will we choose this device because it would, as expected in our professional judgment, lead to better speech understanding performance in the real world?
When a digital hearing aid with a directional system is found to be associated with slightly better SRTs in terms of SNR, many of us would select that hearing aid and expect to see better speech intelligibility scores when the directional system engages. Likewise, when an assistive listening device (ALD), such as a FM system, shows slightly more benefit in SRT over other devices, many clinicians would also tend to make a reasonable inference that the ALD is going to yield superior speech understanding performance.1
Indeed, the literature has even tried to predict subjects’ speech understanding performance from the sentence recognition threshold based on the slope of the Performance-Intensity (P-I) function curve—from which the sentence recognition threshold was obtained. As only one example, we might read in the literature that “according to the test manual, a 1 dB S/N ratio difference is equivalent to 9 percentage points in the intelligibility of sentences. Thus, a 4 dB difference in S/N ratio between groups implies speech intelligibility scores approximately 36% poorer in the bilingual than the monolingual native speakers.”
Evidently, the underlying assumption for all these approaches is that one can make a prediction or an estimation of an individual’s speech intelligibility performance from the SRT. However, is this widely accepted approach precise enough for clinical use? Can we actually be able to estimate or predict a hearing aid user’s speech understanding score simply based on that 50% point?
Theoretical Considerations
Like the puretone threshold (PT), which is the softest level at which the puretone signal is barely perceptible 50% of the time, the Speech Recognition Threshold (SRT) is the threshold level at which the speech signal is barely recognizable 50% of the time.3-5 Again, like the puretone threshold—which represents an individual’s hearing sensitivity to puretone signals—the SRT represents an individual’s hearing sensitivity to speech signals. By definition and the nature of the testing procedure for threshold determination, the SRT indicates a response of the individual to speech signal at the threshold level. This is an important nuance: The SRT indicates the response to speech signals when the speech signal is presented at a fairly soft level such that it is just almost perceptible/recognizable for about 50% of the time. Since the speech signal is at that barely recognizable level and guesswork is naturally involved during testing, the SRT is the threshold level response, standing apart from suprathreshold level response of the individual.
On the other hand, the Word Recognition Score (WRS) represents all possible responses when the speech signal is presented at various loudness levels above the individual’s threshold.3-5 The WRS shows how well the patient can hear and process speech signals at various supra-threshold levels; in contrast, the SRT indicates how sensitive the person is to hearing speech signals at specific barely perceptible levels. Therefore, compared to plotting all possible WRS responses as a function of signal presentation levels, the SRT is known in the field as the 50%-point on the Performance-Intensity curve. The take-home point here is that the SRT is the threshold level response whereas the WRS is the supra-threshold level response to speech stimuli; by no means does the SRT indicate or hint at supra-threshold responses.
Examining SRT and WRS for Different Types of Hearing Loss
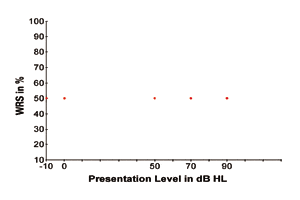
To illustrate the above, Figure 1 shows four hypothetical SRTs displayed as four data points as a function of WRS (versus presentation levels of the speech signal). The four data points represent the softest signal level at which the speech signal is barely perceptible 50% of the time for individuals with normal hearing sensitivity and various degrees of hearing loss of around 50 dB, 70 dB, and 90 dB HL. The four data points also indicate that the word recognition performance is 50% since individuals of the four types of hearing status can only recognize the speech signals with 50% accuracy when speech signals are presented at their threshold levels, respectively.
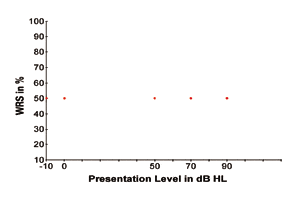
Then, what would the performance-intensity curve look like when speech signals are presented at their suprathreshold levels? Based on these four data points, can we estimate their maximum word recognition scores when speech signals are presented at various higher levels? Similarly, if these four data points represent the SRTs with an appropriately-fitted hearing aid in use, are we able to predict a subject’s maximum speech intelligibility score after receiving the benefit of a hearing aid?
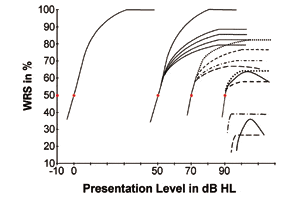
Figure 2 may serve to answer these questions. Based on clinical experiences and theoretical considerations, examples of some hypothetical Performance-Intensity (P-I) curves were plotted to demonstrate the interrelationship and response pattern of subjects’ word recognition scores for individuals with normal-hearing status and various degrees of hearing losses.
For normal-hearing status. In Figure 2, the curve on the far left (eg, passing the 0 dB presentation level) may be used as the curve representing normal-hearing individuals. This is the one frequently seen in textbooks indicating that performance increases along with the increase of signal presentation level with a fixed slope, if measured with a fixed testing procedure and a given speech-testing material. Performance reaches the maximum WRS at about 40 dB Sensation Level (SL) above the SRT.
For 50 dB-hearing losses. In Figure 2, to the right of the curve for normal-hearing individuals, a group of curves passing the 50 dB presentation level represents typical responses on the WRS for the 50 dB-hearing-loss category of listeners. Among this 50 dB-hearing-loss category (5 solid-line curves), the curve on the left shows the P-I function when the 50 dB hearing loss is a conductive hearing loss in nature. Note that the curve is exactly the same slope and reaches the same maximum WRS as the one of normal-hearing subjects because conductive hearing loss is, by nature, a sensitivity loss involving no pathology in the inner ear and higher structures.
When the 50 dB hearing loss involves mixed hearing loss in nature (eg, a mild component of sensorineural hearing loss), then the subject’s signal processing ability is reduced. Their P-I curves (the other 4 solid curves in this group of curves) might still ascend, but with a steeper slope and become flattened at a lower maximum WRS, compared to the curve of the normal-hearing subjects or of the conductive hearing loss.
From this 50 dB-hearing-loss category, it can be seen that all curves show the same SRT but with large individual difference in the maximum WRS—ranging possibly from near 70% to 100%.
For 70 dB hearing-losses. Further to the right in Figure 2, there are 4 dashed-line curves passing through the 70 dB SRT data point, culminating a different maximum WRS. These represent the possible response patterns and individual differences on the P-I function for the 70 dB-hearing-loss category. The category of hearing loss around 70 dB SRT is usually the majority of the client population seen in the “typical” hearing aid clinic.
It should be immediately apparent that greater variations in the maximum WRS, as shown in Figure 2, can result from this type of loss. It is also interesting to note that some dashed-curves reach a WRS performance higher than those in the 50 dB-hearing-loss category, while others show a performance that is, in general, lower. One curve (the bottom dashed-line curve) shows a small degree of rollover phenomenon: poorer WRS at higher presentation levels once the highest WRS is reached.
The great amount of individual variation revealed from the P-I curves is often related to sensorineural hearing loss (SNHL) with hair-cell and neural-fiber pathology involved. These losses often feature both a sensitivity loss and a clarity loss component, with the clarity loss in speech signals varying dramatically depending on such factors as, but not limited to, degree of hearing loss, shape of hearing loss, etiology of hearing loss, pathological condition of the ear-brain structure, extent of damage to outer hair cells and/or inner hair cells, damage and effect on active cochlear amplification, residual function of inner hair cells, damage to retrocochlear nerve fibers, effect on neural discharge synchrony, proportion of retrocochlear lesion versus cochlear lesion, effect of tonotopic reorganization of auditory cortex, length of hearing loss, history of hearing aid use, amount of time associated with (in)adequate auditory stimulation, prelingual versus postlingual cases, lifestyle and living surroundings, an an individual’s linguistic ability (see sidebar, “Is There Such a Thing as a Typical 70 dB Hearing Loss?”).
Clearly, myriad factors as discussed in the sidebar—including those in pathological and linguistic domains—interact with each other as the underlying mechanisms influencing the speech signal processing performances. Therefore, large individual differences on the response pattern of speech signal processing, slope of the P-I curve, and maximum WRS, should be reasonably expectable among subjects. For the 70dB-hearing-loss category of SNHL, what is displayed in Figure 2 is only a portion of the possible P-I functions with various maximum WRS achieved—all with a same SRT.
Therefore, Figure 2 and common sense suggest that predicting the possible maximum WRS from the SRT is a foolhardy approach without appropriate caveats.
For 90 dB hearing losses. When the degree of hearing loss moves to the 90 dB-hearing-loss category, the SNHL would normally involve the neural component to complement the sensory component, yielding far greater losses in signal clarity along with sensitivity loss. These types of losses suggest more damage in the retrocochlear region and other neural relay stations along higher auditory pathways. Thus, more neurological impairments on higher pathways, with a greater chance of neural discharge dys-synchrony and auditory processing disorders, may become a possibility and reveal even poorer signal processing performance (compared to the 70 dB-hearing-loss category). All the factors discussed above—such as the actual degree of hearing loss across frequencies, particular etiology, location and severity of the damage in the inner ear and auditory pathways, tonotopic reorganization, individual’s linguistic ability, etc—would interact with each other and result in different response patterns and slopes of the P-I curve. Again, large variations in the maximum speech signal processing performance would be expected.
In Figure 2, three curves (two dashed and one solid line curves passing the 90 dB data point) were plotted to show varying slopes with various maximum WRS that may be achieved by individuals in this category of hearing loss. The solid-line curve shows even greater roll-over phenomenon as compared to that of the 70-dB-hearing-loss category. All three curves are placed to show that their maximum WRS is likely to be lower than that of the 70-dB-hearing-loss category.
Of course, we know that some subjects with around 90 dB hearing loss would show extremely and exceptionally good WRS in comparison to those with even mild hearing loss. This kind of exception is not altogether uncommon; it further supports the great variability in signal processing performance functions and the auditory system. The unique point of discussion here is that all these curves are passing through the same 90 dB SRT data point and yielding a radically different maximum WRS. As with the 70 dB loss group, there are large individual differences.
In the right-bottom corner of Figure 2, three more curves are displayed, showing some possible P-I curves for those with hearing loss greater than 90 dB HL. With this profound degree of hearing loss and confounding factors (as discussed above), large individual differences in the slope of the response curve and the maximum WRS should be anticipated.
The uniqueness of these three curves is that the subjects’ ascending speech recognition performance may not even be able to reach the 50% point. Additionally, both the maximum WRS and rollover phenomenon may be even poorer or more pronounced, respectively, than “70 dB losses.”
Clinical Evidence
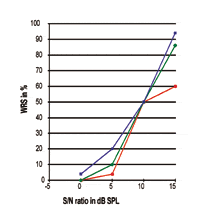
Some empirical clinical data may be useful to demonstrate the above. In an attempt to study the effect of compression threshold on speech intelligibility, 12 subjects with mild-to-severe SNHL above 2 kHz listened through a programmable hearing aid to the target sentences of the Speech In Noise (SIN) test. Examples of the speech-processing performance of these subjects were selected and plotted as P-I curves relative to SNR (Figures 3-6).
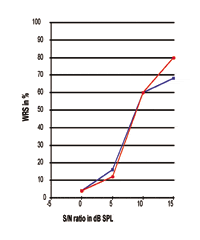
Referring to Figures 3-5, it is clear that different subjects’ WRS performances may be exactly the same at the 50% point, while the slope of the curve and the maximum performance are completely different from one another. All these curves show that the SRT is, indeed, only the 50% data point along the response curve; great differences with respect to the slope of the curve and maximum processing performance exist in the real world. The figures indicate that the 50% data point has no close relationship with the maximum processing performance that would be accomplished by the individuals. Thus, the SRT should not be used as being representative for the performance-intensity responses.
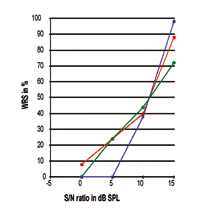
This information also suggests that, when advising graduate students and formulating research projects, it may not be wise to use the SRT as the primary criteria of the study. Although quite a few tests are now designed to find the 50% point of subject’s speech processing performance, the interpretation of the 50% point or SRT—either expressed in terms of the presentation level or SNR—should be made with caution. Speech processing performance is a more complicated phenomenon.
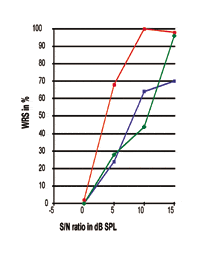
| In Figure 6, the three individual P-I curves are with a totally different 50% point. The red curve represents an individual with mild high-frequency SNHL, while the other two curves were obtained from individuals with moderate-to-severe high-frequency SNHL. In fact, the steep slope and the near-perfect speech processing performance demonstrated by the red curve are similar to responses achieved by normal-hearing subjects.
This might be expected, since subjects with mild sensorineural hearing loss may suffer from less damage in the ear-brain system. For the curves obtained from individuals with moderate-to-severe high-frequency SNHL, greater degrees of individual differences may be seen, as discussed earlier. While observing these two curves, note that the one with the better 50% point (blue curve), compared to the green curve, does not yield a better WRS. This indicates that, in the real-world where individual variations exist, a better 50% point (SRT) is not always associated with better maximum speech processing performance. |
Summary
1) An individual’s speech processing performance is dynamically affected by a number of factors including degree, type, shape of hearing loss, length of hearing loss, and many other pathophysiological conditions in the ear-brain system and even the individual’s linguistic ability/profile.
2) Speech recognition threshold is just the 50% data point on the P-I curve of subject’s speech processing performance.
3) An individual’s 50% data point (SRT) on the P-I curve could be at unity with another patient’s, but the slope and the processing performance of these two patients could be completely different from each other.
4) The relationship among the response pattern, the SRT, the slope of the P-I curve, and the maximum processing performance is extremely dynamic and unpredictable due to the individual variability.
5) A response with better SRT is not necessarily associated with better WRS. Although there often appears to be a working assumption/approach in our field for using the 50% data point to predict the maximum speech processing performance, this is in fact an effort without clinical/theoretical foundation and accuracy.
6) When performing hearing aid or ALD fittings—such as selecting, modifying, and fine-tuning, or when establishing realistic expectations for the benefits of amplification—one should not be over-reliant on the 50% data point. Instead, obtaining a more complete P-I curve with maximum speech processing performance is a more pragmatic approach for the real-world clinician.
| Is There Such a Thing as a “Typical” 70 dB Hearing Loss? |
| It is apparent that more severe hearing losses can bring about fairly remarkable variations in the WRS. Hearing losses above 70 dB are often complex and multifaceted. For example, those patients with 70 dB SRT scores may have totally different puretone thresholds across frequencies. In other words, patients may have various magnitudes of hearing loss at discreet puretone frequencies, but all may appear to have a SRT around 70 dB HL. The individuals may also have different audiogram shapes, including a flat, sloping, low frequency, high frequency, precipitous, or even a “cookie-bite” hearing loss, but still show a SRT of about 70 dB HL.
This means that the location and severity of damage over the high versus low frequency region (eg, basal versus apical) of the basilar membrane in the inner ear could be quite different among these subjects. Further, varying degrees of damage would be induced on the active cochlear amplification function; different outer hair-cell electromotility would lead to different abilities of hearing sensitivity and frequency discrimination of signals.6-9 All these pathological conditions would result in signal processing with poor hearing sensitivity and reduced frequency analysis, plus differing amounts of distortion when processing consonants and vowels. And, in turn, these would be reflected by various speech recognition scores. If the pathology involves more damage over inner versus outer hair cells, its effect on signal processing and the amount of distortion during signal processing would likely be greater and higher, because 95% of the auditory nerve fibers carry information from the inner hair cells while only about 5% of auditory nerves innervate the outer hair cells.9-10 When the pathology occurs more in the retrocochlear than cochlear region, greater amount of clarity loss and the rollover phenomenon in speech recognition might be expected. It is also known that, with damage to the higher auditory pathways, the higher-level processes such as auditory figure-ground differentiation, binaural integration, binaural separation, and release from masking might all be affected. This might also lead to varied and seemingly disproportionately poorer speech recognition in the listening-in-noise tasks.11,12 Various etiologies like bacterial/virus inner ear infection, noise/drug-induced hearing loss, blood circulation/hemorrhage phenomenon, acoustic neuroma, APD and auditory dyssynchrony, autoimmune inner ear disease, and hereditary hearing loss may result in pathological conditions that produce different locations and severities of the damage over the sensory/neural structures with resulting speech recognition performances still being associated with a 70 dB SRT.11,12 Another factor comes from the area of tonotopic reorganization of the auditory cortex of animal subjects suffering from SNHL. It is known that, with SNHL sustained over time, an expanded monotonic area in the auditory cortex is established in which the neurons have their original characteristic frequency changed to a new (lower) frequency. Their tuning curves show elevated thresholds, poor frequency discrimination, and hypersensitivity to frequencies other than their original characteristic frequency.13,14 It has also been suggested that this tonotopic reorganization—an effect due to brain plasticity in response to the inadequate and asymmetrical auditory stimulation over time—is closely related to the auditory deprivation/adaptation in human subjects who have poor WRS on monosyllabic words and sentences, and even with other high-level signal processing performances involving binaural separation and integration.13-17 Here, for the subjects of the 70 dB-hearing-loss category, their different degrees of hearing loss across frequencies, different locations/severities of damage, and many other variables may all add up as confounding factors for the formation of tonotopic reorganization of the auditory cortex. This means that, among subjects of this category, a different monotonic area in the individual’s auditory cortex loses its original signal processing abilities. It becomes tuned to a different frequency, various percentages of the neurons become less-sharply tuned, and unique changes in iso-frequency contour arrangement in the cortex can occur, as can varying degrees of threshold elevation and hypersensitivity of neurons to frequencies other than their “best frequency.” Various reductions in frequency discrimination and other higher neurological processing abilities should then be expected. These different features of the resulting tonotopic reorganization, in turn, lead to variations in subject’s performance in background noise, signal processing, and frequency and intensity resolutions—all resulting in differences in speech recognition. Further, there is no doubt that each individual’s linguistic ability is a large macrovariable in that person’s speech understanding performance. People’s linguistic abilities—their skills in semantic form, syntactic structure, and pragmatic language use, etc—differ and may help or hinder them during communication breakdowns (eg, when trying to “fill in the blanks” using linguistic and contextual cues). For those in the 70dB-hearing-loss category, who already have difficulty in understanding speech, linguistic ability would be a macrovariable interacting with their hearing loss and influencing WRS, especially when the WRS is measured using sentence materials in background noise. Additionally, the complexity of the linguistic profile for bilingual people can be compounded by variables such as age of second-language acquisition, language of parents, geographic origin of acquisition, language use, length of exposure to the second language, etc, and all these variables are influential in speech/language processing performance, especially during listening-in-noise tasks.18-20 |
References
1. Lewis MS, Crandell CC. Frequency modulation (FM) technology applications. Presented at: The 17th Annual Convention of American Academy of Audiology (Instructional course IC-103), Washington, DC;2005.
2. Von Hapsburg D, Pena E. Understanding bilingualism and its impact on speech audiometry. J Speech Lang Hear Res. 2002; 45: 202-213.
3. Newby HA, Popelka GR. Audiology. 6th ed. Englewood Cliffs, NJ: Prentice Hall Inc; 1992:126-201.
4. Stach BA. Clinical Audiology: An Introduction. San Diego, Calif: Singular Publishing Group Inc; 1998:193-249.
5. DeBonis DA, Donohue CL. Survey of Audiology: Fundamentals for Audiologists and Health Professionals. Boston, Mass: Allyn and Bacon; 2004:77-164.
6. Brownell W, Bader C, Bertrand D, de Ribaupierre Y. Evoked mechanical responses of isolated cochlear outer hair cells. Science. 1985;227(11):194-196.
7. Dallos P, Evans B, Hallworth R. Nature of the motor element in electrokinetic shape changes of cochlear outer hair cells. Nature. 1991;350(14):155-157.
8. Dallos P, Martin R. The new theory of hearing. Hear Jour. 1994; 47(2):41-42.
9. Ryan AF. New views of cochlear function. In: Robinette MS, Glattke TJ, eds. Otoacoustic Emissions: Clinical applications. 1st ed. New York, NY: Thieme Medical Publishers Inc; 1997:22-45.
10. Gelfand SA. Hearing: An Introduction to Psychological and Physiological Acoustics. 3rd ed. New York, NY: Marcel Dekker Inc; 1998:47-82.
11. Mencher GT, Gerber SE, McCombe A. Audiology and Auditory Dysfunction. Needham Heights, Mass: Allyn and Bacon; 1997:105-232.
12. Martin FN, Clark JG. Introduction to Audiology. 9th ed. Boston, Mass: Allyn and Bacon; 2006:277-346.
13. Harrison RV, Nagasawa A, Smith DW, Stanton S, Mount RJ. Reorganization of auditory cortex after neonatal high frequency cochlear hearing loss. Hearing Res. 1991;54:11-19.
14. Dybala P. Effects of peripheral hearing loss on tonotopic organization of the auditory cortex. Hear Jour. 1997;50(9):49-54.
15. Silman S, Gelfand SA, Silverman CA. Late-onset auditory deprivation: Effects of monaural versus binaural hearing aids. J Acoust Soc Amer. 1984;76(5):1357-1362.
16. Palmer CV. Deprivation, acclimatization, adaptation: What do they mean for your hearing aid fittings? Hear Jour. 1995;47(5):10,41-45.
17. Neuman AC. Late-onset auditory deprivation: A review of past research and an assessment of future research needs. Ear Hear. 1996;17(3):3s-13s.
18. Grosjean F. Processing mixed language: issues, findings, and models. In: de Groot AMB, Kroll JF, eds. Tutorials in Bilingualism: Psycholinguistic Perspectives. Mahwah, NJ: Lawrence Erlbaum Associates; 1997:225-251.
19. Mayo LH, Florentine M, Buus S. Age of second-language acquisition and perception of speech in noise. J Speech Lang Hear Res. 1997;40:686-693.
20. Von Hapsburg D, Champlin CA, Shetty SR. Reception thresholds for sentences in bilingual (Spanish/English) and monolingual (English) listeners. J Amer Acad Audiol. 2004;15(1):88-98.
Correspondence can be addressed to HR or Bailey K. Wang, PhD, 1201 West University Drive, Edinburg, TX 78541; email: [email protected].
| Bailey K. Wang, PhD, is an associate professor and audiologist at the Department of Communication Sciences and Disorders, College of Health Sciences and Human Services, University of Texas-Pan American, Edinburg, Texas. |



