People with a precipitous high frequency hearing loss often miss the high frequency information even when they wear hearing aids. Sometimes it is because the high frequency gain available on the hearing aid is not sufficient to reach audibility before feedback occurs; sometimes the severity of the hearing loss in the high frequency region is so great that it is unaidable or “dead” from the complete depletion of inner hair cells.
In the former case, audibility may be achievable at the expense of a smaller vent diameter on the hearing aid. This could compromise wearer comfort because of an increase in the occlusion effect.1 In the latter case, acoustic stimulation of the unaidable region may decrease further the already depressed speech understanding.2 The loss of audibility of high frequency sounds often compromises speech understanding and the appreciation of music and nature’s sounds (such as bird songs).
What is Frequency Lowering?
One of the earlier attempts to achieve audibility for high frequency sounds is the use of frequency lowering techniques. These are simply nonlinear operations in which high frequency sounds are moved to a lower frequency region. When these techniques are applied to hearing aids, the objective is to provide audibility of the “unaidable” high frequency cues by changing them into an audible lower frequency substitute. The target beneficiaries of this technique are people with a severe-to-profound loss in the high frequencies who cannot benefit from conventional amplification.
|
Various approaches had been attempted in frequency lowering. The first attempts were done well before non-linear and digital technology was applied to hearing aids. Methods such as slow-playback, time-compressed slow-playback, frequency modification with amplitude modulation, vocoding, zero-crossing rate division, frequency shifting, and frequency transposition were all major approaches that have been summarized by Braida et al.3
More recent strategies in the area include proportional frequency compression4 and approaches that “sharpen” the spectrum of the transposed sound5 or the various transposed features (eg, voiceless vs voiced). Although these approaches are significantly more complex than earlier attempts and they all resulted in better aided thresholds, their acceptance has been relatively limited.
What Are the Problems?
Limitations of analog signal processing. The early attempts on frequency lowering were designed to achieve easy implementation of existing technologies rather than to achieve the desired signal processing results. Many were not even practical enough to be implemented into hearing aids. While lowering the frequencies, these methods also altered other aspects of speech known to be important for perception. Some of these approaches created unnatural sounding speech, distorted gross temporal and rhythmic patterns, and extended durations (slow playback) of the speech signals. Others created reversed spectrum (amplitude modulation based techniques) which is difficult to even recognize as speech by inexperienced listeners. In vocoder-based systems, both analysis and synthesis were often carried out using only a limited number of frequency bands, which resulted in unnatural speech sounds.
Unnatural sounds. Despite the recent use of digital signal processing (DSP) techniques in frequency lowering, artifacts and unnatural sounds were still unavoidable. Some reported that the transposed sounds are “unnatural,” “hollow or echoic,” and “more difficult to understand.” Another commonly reported artifact is the perception of “clicks” which many listeners find annoying. Such perception would most likely be exaggerated when the transposed sounds and the original sounds do not overlap. Thus, despite its potential for speech intelligibility improvement with extensive training, many adults found it difficult to accept frequency lowering.
Insufficient training and limited evaluation. It would be highly desirable that the new acoustic cues resulting from frequency lowering resemble the original high frequency sounds in some meaningful, easy-to-interpret manner. Nevertheless, these processed sounds were never heard by the hearing-impaired listeners before. As such, it is unrealistic to expect the listeners to identify the new sounds without adequate training and experience. Unfortunately, most previous studies have not given the test subjects time to adjust to and learn to use these new acoustic cues. In studies where extensive training was provided, marginal improvement in speech understanding was observed.6
Considerations in Frequency Lowering
Minimization of artifacts and unnatural sounds. Minimal artifacts or unnaturalness will result if the frequency lowering method retains the relationships of the original frequency components in the final signal. Preferably, the relationships of the harmonic components stay the same, the spectral transitions move in the same direction as the original un-transposed signal, and the segmental-temporal characteristics stay untouched. One should not remove or sacrifice any acoustic cues that the listeners are using before frequency lowering. In addition, the processed speech signal should retain the extra-linguistic (prosodic) cues, such as its pitch, tempo, and loudness. Otherwise, it will make it more difficult for the listeners to accept the new sound images initially and lengthen the training and relearning period.
One criterion is to lower only the frequencies that are necessary to be lowered (instead of the full range of frequencies). For example, if someone has aidable hearing up to 3,000 Hz, one should only process (or lower) sounds above 3,000 Hz. This has the advantage of focusing only on sounds that are relevant.
Another criterion is to apply the “right” amount of processing for the individual. This is because the more aggressive the lowering (eg, higher frequency compression ratio), the more unnatural the sound percept becomes. A conservative or less aggressive approach will minimize the disturbance on the original signals and avoid any potential interaction between the original signals and the processed signals.
A final criterion is to preserve the temporal structure of the original signal in order to retain any transition cues. This means the frequency lowering system must have the flexibility and specificity to meet individual wearer’s needs.
In cases where the unnaturalness is unavoidable because of the extent of frequency lowering, a strategy to minimize the exposure of artifacts is to make the frequency lowering algorithm optional. That is, the wearer will only listen to the processed sounds when he/she needs to. In situations where such a program is not needed or not beneficial, the program may be deactivated.
Proper training and evaluation. The need for training may be argued if frequency lowering has completely altered the acoustic cues available to the wearers. Consequently, frequency lowering technique should use a two-prong approach. First, it should preserve the existing cues while adding new ones. This requires special attention be paid to the individuals’ hearing needs and the flexibility with the programming to accommodate such needs. Second, it should recommend an appropriate training program with the algorithm to further realize the potential of the transposition. In practice, this means that the frequency lowering algorithm should receive high initial acceptance for daily stimuli such as nature’s sounds. But a structured training program that is directed towards improving sound recognition should also be available for those who needed the training. These criteria mean that the chosen frequency lowering algorithm must be appropriate for both speech and non-speech sounds.
Extending Audibility via Linear Frequency Transposition
These considerations guided the development of the new, patent-pending Audibility Extender (AE) algorithm in the recently introduced Widex Inteo hearing aid. The AE is one form of frequency lowering technique that uses Linear Frequency Transposition to move the unaidable high frequency sounds to the aidable low frequency regions.
A feature of this algorithm is its inclusion in the Integrated Signal Processing (ISP) platform6 used in the Inteo. Briefly, ISP integrates information of the wearers, the environments, as well as the intermediate processing of each algorithm into the Dynamic Integrator (DI). In turn, the DI coordinates all the activities and dispatches the appropriate commands to each algorithm so that the processed sounds would be as natural as possible with little or no artifacts.
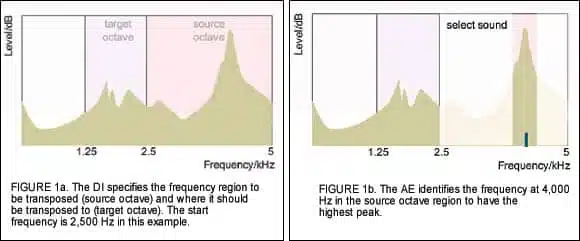
How it works. First, the Inteo AE receives information of the wearer’s hearing loss from the Dynamic Integrator (provided from Wearer’s Personal Information) to decide which frequency region will be transposed. The frequency where transposition begins is called the Start Frequency. Typically, one octave of sounds above the start frequency will be transposed. This is called the source octave. (Figure 1a).

Meanwhile, the Speech and Noise Tracer of the HD System Analysis module performs its spectral analysis of the environment and returns the results to the Dynamic Integrator. The AE picks the frequency within the “source octave” region with the highest intensity (eg, peak frequency), and locks it for transposition. As the peak frequency changes, the transposed frequency also changes. In the example, 4,000 Hz has the peak intensity (Figure 1b). Once identified, the range of frequencies starting from 2,500 Hz will be shifted downward to the target frequency region. In this case, 4,000 Hz (and the sounds surrounding it) will be transposed linearly by one octave to 2,000 Hz (Figure 1c).
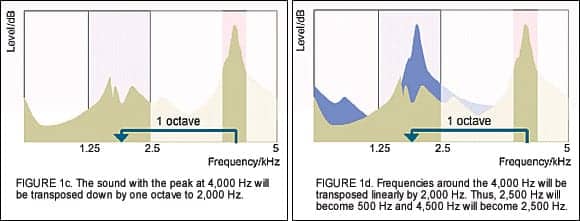
The 4,000 Hz signal will be placed at 2,000 Hz and every frequency will be shifted down by 2,000 Hz. For example, 3,000 Hz will now be at 1,000 Hz and 4,500 Hz will be at 2,500 Hz (Figure 1d). In this way, the transposed signal is likely to be placed in a region where the hearing is aidable. To limit the masking effect from the transposed signal and any potential artifacts, frequencies that are outside the one octave bandwidth of 2,000 Hz will be filtered out (Figure 1e).
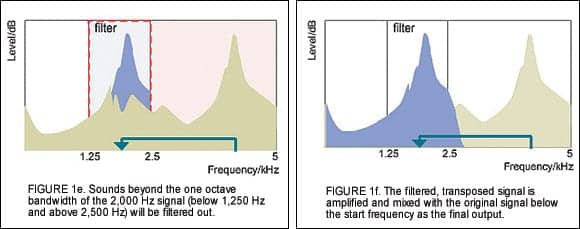
The level of the transposed signal will be automatically set by the AE so it is above the in-situ threshold (sensogram) of the wearer. A separate manual gain adjustment of the transposed signal is also available. The linearly transposed signal is mixed with the original signal below the start frequency (2,500 Hz in this case) as the final output. (Figure 1f).
Other considerations. To ensure ease of use of the AE program, simple default rules are implemented that consider the degree and slope of the audiogram in deciding the default start frequency (for transposition). The optimum start frequency is critical in ensuring acceptance and successful use of the AE.
By definition, the start frequency is the frequency where the hearing loss is unaidable. Thus, instead of amplifying that frequency, the AE transposes it without amplification. Consequently, too low a start frequency (below the optimum) will result in some of the aidable frequencies not being amplified. This removes some of the acoustic cues that are usable by the wearers to result in distortion and unnaturalness of the signal. Too high a start frequency will leave some of the unaidable high frequencies inaudible. In both cases, it will unnecessarily decrease the initial acceptance of the AE and prolong the time to fully realize its potential. To meet the individual hearing needs of the wearers and to increase the flexibility of the AE program, options to manually adjust the start frequency from 630 Hz to 6,000 Hz at 1/3 octave intervals (as well as individualized fitting guidelines) are available.
Another advantage of the AE is that it is an optional program. This means one can set this program as the master default program for use in all listening situations; alternatively, it can be used only in situations where the wearer desires. The former may be a pediatric fitting where the child uses the AE all the time so he or she can hear all the high frequency sounds in many environments for speech and language purposes. The latter may be an adult who is satisfied with the default settings of the hearing aids in most situations, but desires the AE program for listening to birds, music, or other sounds. In this way, individual preferences and usage habits are considered.
How is the Audibility Extender Different?
The Audibility Extender is different from other frequency lowering schemes in several aspects:
1. It transposes only the high frequency sounds (above the start frequency) regardless of their voicing characteristics (eg, voiced or voiceless). Thus, it is equally effective on periodic and aperiodic sounds. Systems that are active only for voiceless signals may miss high frequency periodic signals including music and bird songs.
2. It is active during all segments of speech and not at specific linguistic segments, (eg, voiced versus voiceless).
3. Typically only one octave (although two octaves may be allowed) of high frequency sounds above the start frequency is transposed to a lower octave. Frequencies higher and lower than the transposed region are filtered. This limits the amount of masking and avoids the need for compression.
4. For simple stimuli, it preserves the transition cues and the harmonic relationship between the transposed signal and the original signal. This preserves as much of the original signal as possible.
5. The transposed signal is mixed with the original signal to give a richer, more “natural” sound perception. Systems that do not overlap the transposed sounds would risk “exaggerating” any unnaturalness of the transposed sounds.
6. By transposing frequencies linearly, the temporal structure of the signal is preserved. Thus, it can be easily recognized as the original source signal but at a lower frequency.
Efficacy of the Audibility Extender: Interim Field Report
While clinical studies are being conducted to better understand the efficacy of the AE algorithm, we have completed some preliminary studies that examined the initial subjective preference for the AE using different stimuli.
Subjects. A total of 16 individuals with hearing impairment, primarily with high frequency sensorineural hearing loss, were tested to examine their preference for the AE for bird songs, music, and discourse speech stimuli. Of these subjects, 5 individuals had a precipitously sloping hearing loss with normal hearing below 1000 Hz, and 11 had a sloping high frequency hearing loss of moderate to severe degree.
Hearing devices. All the subjects with a precipitous hearing loss and 6 subjects with a sloping high frequency hearing loss wore the open-fit Inteo élan during the study. The rest of the subjects wore the Inteo IN-9 and IN-X (ITC) with the appropriate vent diameter (1-3 mm diameter). The fitting of the Inteo hearing aids including the AE algorithm, followed the default recommendations (eg, no individual fine-tuning).
Stimuli and testing. Three sets of stimuli were used to evaluate the subjective preference for the AE. A set of 12 bird songs (different species, with mostly high frequency content up to 6,000 Hz), 12 musical passages (including single instruments, ensemble, and songs with lyrics), and 12 short discourse passages read by a female announcer were used. Each stimulus was about 5-10 s in duration. Subjects listened to each stimulus in the AE-On and AE-Off conditions (the same frequency response and feature settings were used between AE-On and Off) and the subjects indicated the setting (eg, AE-On or AE-Off) they preferred for the particular stimulus.
The stimuli were presented in random order and at a comfortable listening level chosen by the subject in the AE-Off condition. The number of stimuli within a stimulus set that the subject preferred with the AE-On was recorded and expressed as a percentage displayed in the following figures.
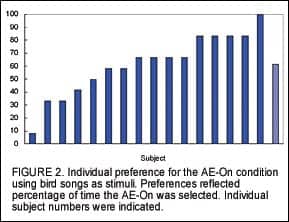
Preference for bird songs. Figure 2 shows the individual preference for AE using bird songs as stimuli. Each bar represents the percentage of time the AE was preferred by a specific subject. For example, a preference of 100% (Subject #18) indicated that the subject preferred the AE-On for all 12 bird songs, whereas a preference of 50% (subject #15) indicated that the subject preferred the AE-On for 6 of the 12 bird songs (the other 6 for the AE-Off). One can see that subject preferences varied dramatically. Subject 9 preferred the AE-On for only one bird song, whereas subject 18 preferred the AE-On for all the bird songs. On average, AE-On was preferred for over 60% of the bird songs.
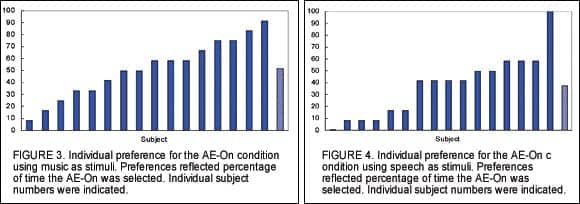
Figure 3 shows the individual preferences for AE using music as stimuli. Similar to using bird songs as stimuli, one sees a range of preferences for the AE from less than 10% to over 90% of the time. As a group, the preference for AE-On was about 50% of the stimuli. These preferences are slightly lower than when bird songs were used as stimuli.
Preference for speech. Figure 4 shows the individual preference when conversational speech passages were used as stimuli. There was an even wider range of preference for the AE, with Subject #7 showing no preference for AE-On (eg, all AE-Off) and Subject #2 preferring only the AE-On condition. As a group, AE-On was preferred for 33% of the stimuli.
Conclusions
There are several observations when one examines the preference data across subjects and stimuli. First, subjects with a sloping high frequency hearing loss subjectively prefer the AE when listening to birds, music, and speech. Second, the preference for the AE-On varied with the complexity of the stimuli. Bird songs are simpler in spectral content than music and speech, and the preference for the AE was the highest for birds (over 60%), less for music (55%), and least for running speech (33%). This suggests that the simpler the stimuli, the higher the preference for the AE.
Every subject preferred the AE-On for at least one stimulus. However, subject preference for AE in one stimulus category does not predict preference in another stimulus category. For example, Subject #18 preferred the AE-On 100% of the time when listening to bird songs, but less than 10% of the time when it comes to music and speech stimuli. Whereas Subject #2 preferred AE-On 100% of the time when listening to running speech, he only preferred it 33% of the time when listening to bird songs.
It needs to be emphasized that the above performance was noted when the subjects were initially fitted with the default settings without additional fine-tuning to the wearer’s hearing needs. Furthermore, no experience with the transposed sounds was provided prior to the study. With additional experience and fine-tuning, one would have considered the individual hearing needs in setting the optimal transposition parameters. This could further improve the preference for the AE. This is being evaluated and will be reported later.
With appropriate training and fine-tuning, Linear Frequency Transposition may improve the recognition of high frequency words for those who are limited by their high frequency hearing loss. This could be especially beneficial for children during critical speech and language development periods. Another potential application is in open-fittings where this algorithm increases the audibility of high frequency sounds while open-fit provides excellent listening comfort.
References
1. Kuk F, Ludvigsen C. Amplcusion Management 101: Understanding variables. The Hearing Review. 2002;9(8):22-32.
2. Moore B. Dead regions in the cochlea: conceptual foundations, diagnosis, and clinical applications. Ear Hear. 2004;25(2):98-116.
3. Braida L, Durlach I, Lippman P, Hicks B, Rabinowitz W, Reed C. Hearing Aids—A Review of Past Research of Linear Amplification, Amplitude Compression and Frequency Lowering. In: ASHA Monographs; No 19. Rockville, MD: ASHA;1978.
4. Turner C, Hurtig R. Proportional frequency compression of speech for listeners with sensorineural hearing loss. J Acoust Soc Am. 1999;106(2): 877-886.
5. Aguilera-Muñoz C, Peggy B, Rutledge C, Gago A. Frequency lowering processing for listeners with significant hearing loss. In: Proceedings of the Sixth IEEE International Conference on Electronics, Circuits and Systems (Cat. No.99EX357), Part 2(2); 1999:741-744.
6. Kromen M, Troelsen T, Pawlowski A, Fomsgaard L, Suurballe M, Henningsen L. Inteo—A Prime Example of Integrated Signal Processing. In: Integrated Signal Processing—A New Standard in Enhancing Hearing Aid Performance. Long Island City, NY: Widex Hearing Aid Co; 2006.



