
This paper provides an overview of the nature of severe to profound sensorineural hearing loss, unique characteristics of the patients with this disorder, and the signal processing approaches that can be utilized to manage it effectively.
It is estimated that about 11% of all people with hearing loss have a severe to profound hearing loss.1 Since this percentage is not nearly as large as the percentage of people with mild to moderate hearing loss, there is a general lack of understanding of their unique audiological characteristics and rehabilitation solutions.



This article was submitted to HR by Ravi Sockalingam, PhD, Aud(C), and Peter Lundh, MSc, who are senior audiologists at Oticon A/S, Smørum, Denmark, and Donald J. Schum, PhD, vice president of audiology and professional relations at Oticon Inc, Somerset, NJ.
With the growing use of cochlear implants, there has been a decrease in the attention paid to the fitting of acoustic amplification in the severe to profound hearing loss patient group. However, not all patients in this group become cochlear implant users, and even those who do are increasingly utilizing bi-modal fittings (the combination of cochlear implants and hearing aids). Therefore, it is important for the clinician to be aware of the modifications in standard fitting approaches that make sense for this patient group.
This paper provides an overview of the nature of severe to profound sensorineural hearing loss, unique characteristics of the patients with this disorder, and the signal processing approaches that can be utilized to manage it effectively.
Characteristics of Severe to Profound Hearing loss
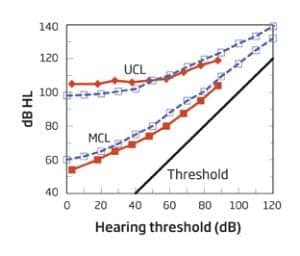
FIGURE 1. Uncomfortable listening level and most comfortable level for people with sensorineural hearing loss, averaged across 500, 1000, 2000, and 4000 Hz from two different studies. Figure adapted from Harvey Dillon’s Hearing Aids (Chapter 9, Figure 9.1), Boomerang Press, Sydney, Australia.
Sensorineural hearing loss is associated with altered loudness perception and reduced dynamic range—less distance between hearing threshold and uncomfortable loudness levels (UCLs). In other words, the UCLs do not increase at the same rate as the hearing thresholds (Figure 1). For people with severe to profound hearing loss, this dynamic range can be as little as 30 dB or even less. And because of this extremely narrow range, providing amplification above the hearing threshold levels without exceeding the UCLs can be rather challenging.
Achieving audibility across a range of frequencies is necessary for optimal speech perception, and providing as much auditory information as possible to attain maximal speech recognition is of paramount importance to individuals with severe to profound hearing loss. However, simply amplifying speech to supra-threshold levels may not necessarily result in better speech perception, as these individuals have difficulty processing supra-threshold speech. In fact, their speech recognition may get worse with amplification.2
There are two reasons for this phenomenon. First, at higher outputs, a broader region of the cochlea is stimulated and the accuracy of speech decoding diminishes.3 For this reason, lower sensation levels for higher outputs are employed in DSL[i/o] and NAL-NAL1 prescriptive formulae.
Second, any hearing loss results in loss of auditory resolution. Both frequency and temporal resolution can be expected to be reduced. Loss of frequency resolution or selectivity stems from a broadening of the auditory filters, which allows noise to pass through and mask speech easily. This broadening, an inherent limitation of the auditory system, is especially pronounced in individuals with severe to profound hearing loss.4 This explains why these individuals experience significant difficulty with speech perception in noise.
The temporal resolution of individuals is often reported to be reduced in hearing loss; their ability to accurately encode the timing of auditory events is disrupted. This phenomenon is marked by poorer performance on temporal tasks such as gap detection, temporal integration, and temporal summation compared to people with normal hearing.5 However, the performance was found to be dependent upon the presentation level of the signal and the presence of neurons in the frequency region tested. Performance is better at higher signal sensation levels and when there are neurons available to respond to the signal. Interestingly, it was found that low frequency temporal resolution in individuals with severe to profound hearing loss and in individuals with normal hearing was much the same. What differed between the groups was the temporal resolution in the mid and high frequencies.6
There is a clear and widely accepted link between the loss of temporal and frequency resolution and poor speech recognition. Speech scores have been reported to be worse in people with severe to profound hearing loss compared to what their pure-tone audiograms suggest.7
If this is the case, what strategies do these individuals use to understand speech? For one thing, individuals with severe to profound hearing loss, compared to people with lesser degree of hearing loss, depend heavily on visual cues (such as speech lip reading) in the presence of background noise. While their ability to resolve the differences between sounds in the frequency domain is compromised, their ability to process sounds in the temporal domain is relatively intact particularly in the lower frequencies. It is this ability to utilize information from the amplitude-time waveform that helps them to decode speech. The temporal waveform also aids in the perception of suprasegmental cues of speech, such as stress, pauses, and intonation. These features may provide additional benefit in difficult listening situations as they embody the true emotions and the intended meaning of speech.8
Managing Severe to Profound Hearing Loss
As mentioned earlier, the dynamic range of hearing in severe to profound hearing loss is significantly restricted. Within this narrow dynamic range, differences may exist between individuals in terms of auditory resolution. While some individuals may be able to decode speech successfully using temporal cues, others may need the extra help from visual cues.9
Such differences between individuals aside, careful application of amplification and automatics (directionality, noise reduction, etc) to achieve maximum comfort, audibility, speech intelligibility, and sound quality is vital. These individuals are long-term hearing aid users and are very conscious of the slightest change in the level or the quality of the sound from their hearing instruments.
Amplification Strategy: Compression and Prescriptive Formula
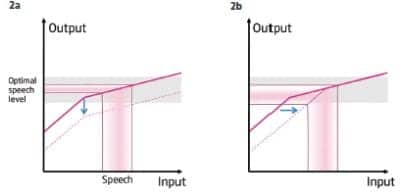
FIGURE 2. Input-output graphs of (left, 2a) a traditional gain reduction system to control feedback that results in significant reduction in the audibility of speech, and (right, 2b) the DSEsp system that shifts the compression threshold to the right (effectively to a higher input level) thus allowing the speech to be processed more linearly and at the same time controlling feedback.
The design of any hearing instruments for severe to profound hearing losses will need to consider the psychoacoustic effect of the hearing loss. Historically, linear amplification with peak clipping was the strategy of choice for them. Even to this day, a severe hearing loss demands the highest possible power of the hearing aid. Additionally, for the attainment of satisfactory gain, the hearing aid would have to work linearly for a significant part of the frequency range.
There were, however, limitations with using a fixed amount of gain for all inputs. With linear amplification, soft input sounds were not amplified loud enough, and loud input sounds were amplified too loud—often exceeding the UCLs. Wide dynamic range compression (WDRC) offered a solution to these limitations and quickly became the amplification scheme of choice for providing audibility across a range of input levels for individuals with severe to profound hearing loss. With WDRC, it was possible for all sounds to be “squeezed” into the restricted dynamic range of hearing that these individuals have. Audibility is achieved across a range of input levels, but with a cost: sound quality. For severe to profound hearing loss, WDRC is typically implemented with a high compression ratio and fast-acting compression to maximize audibility.10 Both of these parameters distort the amplitude-intensity envelope of speech, consequently degrading sound quality. Distortion is an inevitable by-product of WDRC, and for a long time, wearers of WDRC aids had to contend with distortion; audibility was the main priority for them and sound quality was forced to take a back seat.
A slow-acting compression with its long time constant behaves more like a linear amplification system. It protects the amplitude-time envelope of the speech signal, and preserves the dynamic phoneme to phoneme relationship that determines the fidelity of the signal. However, as with linear systems, slow-acting compression may not provide adequate gain for low intensity sounds. Nor would it protect the hearing from loud sounds. However, by using fast attack and release times for sudden loud sounds, such a system can provide protection from loud transient sounds.
A novel amplification system, Speech Guard, that is currently employed in Oticon’s new super power instrument, Chili, is designed to do just that. It processes the signal in a near-linear manner as long as the input signal level remains stable. When the input signal changes dramatically in level (ie, becomes too soft or too loud), it compresses the signal. For the sudden loud sounds, the very fast attack and release times help keep the signal below the MCL. This way, the output signal is always within the dynamic range (ie, audible) and comfortable with minimal distortion. Speech Guard essentially processes speech linearly as long as possible and compresses it quickly when it has to, hence combining the best of both linear and non-linear systems without the pitfalls of either.11 Just how the Speech Guard works has been extensively described elsewhere12 and is beyond the scope of this paper. Speech Guard has already been clearly demonstrated to improve speech intelligibility and reduce listening effort in noise13 for individuals with mild to moderate hearing loss.
Prescribing the right amount of gain is the key function of any amplification system. The fitting or prescriptive formula has to work in concert with the compression system to produce an output signal that is clear, audible, and comfortable for a particular hearing loss. The amplification strategy of the hearing loss is typically based on the principle of loudness compensation. In severe to profound hearing loss, this loudness compensation is somewhat altered when every attempt is made to maintain the amplitude-time structure of the amplified speech.
Loudness modeling studies carried out at Eriksholm Research Centre have given the basis for the loudness compensation for severe to profound hearing loss.14 Any gain targets for severe to profound hearing loss should take into consideration the risk of feedback, since the hearing instruments for these losses are typically used at higher outputs.
In view of this, a prescriptive formula known as Dynamic Speech Enhancement, or Super Power (DSEsp), was developed by Oticon A/S with the goal of prescribing sufficient sensation level of speech without reaching the feedback limit while ensuring reasonable amplitude-time envelope of the amplified speech signal.
Acoustic Feedback
Feedback is generally controlled by reducing gain in frequency channels where the risk of it occurring is high. However, this gain reduction results in undesirable loss of audibility of speech in frequency regions where feedback occurs. DSEsp minimizes this drop in the speech signal by shifting the compression threshold or knee point to a higher level, allowing speech to be processed without further gain reduction. As a result, the gain for soft sounds such as air-conditioning and ventilation noise (ie, unwelcome noises that mask the target speech signal) is reduced.
The reduced gain for soft sounds also helps achieve another important goal in amplification: preserving the speech dynamics and the quality of speech by allowing the signal to be processed more linearly particularly across the speech spectrum (Figure 2).
Directionality
Another important consideration in the management of severe to profound hearing loss is the use of directional microphones to improve speech intelligibility in noise. A significant signal to noise ratio improvement of 9 dB has been demonstrated for this group of clients.15 When directionality is engaged, sounds from the sides and the back are attenuated so that the listener is able to focus and attend to the speech at the front.
A side effect of traditional directionality is that some of the low frequency information is lost. This can pose a serious limitation to listeners if their residual hearing is mainly in the low frequencies. People with severe to profound hearing loss have long-standing experience with hearing aids and may react negatively to the effects of directionality: reduction in audibility of low frequency sounds as well as sounds emanating from the sides and the back. These individuals may have relied heavily on these sounds for successful listening.
One solution to counteract the effects of low frequency attenuation is to use a type of directional system that is used in Oticon hearing instruments: High Frequency Directionality. With such a split directional system, the hearing aid would be in the omni-directional mode in the low frequencies and in directional mode in the high frequencies.
Summary
People with severe to profound hearing loss represent a distinct group of individuals with distinct needs. There are many important considerations when managing severe to profound hearing loss: amplification strategy, feedback, and directionality. Digital signal processing technology, if judiciously and carefully applied, can provide many benefits in terms of audibility, speech understanding, and comfort.
References
- Flynn M, Schmidtke T. Four fitting issues for severe or profound hearing impairment. Hearing Review. 2002;9(11):28-33
- Ching TYC, Dillon H, Byrne D. Speech recognition of hearing-impaired listeners: Predictions from audibility and the limited role of high-frequency amplification. J Acoust Soc Am. 1998;103:1128-1140.
- Gulick L, Gescheider G, Frisina R. Hearing: Physiological Acoustics, Neural Coding, and Psychoacoustics. New York: Oxford University Press, 1989:161-187.
- Faulkner A, Ball V, Rosen S, et al. Speech pattern hearing aids for the profoundly hearing impaired: Speech perception and auditory abilities. J Acoust Soc Am. 1992; 91:2136-2155.
- Humes L. Spectral and temporal resolution by the hearing impaired. In: Studebaker GA, Bess F, eds. The Vanderbilt Hearing Aid Report. Monographs in Contemporary Audiology. Upper Darby, Pa: 1982:16-31.
- Rosen S, Faulkner A, Smith D. The psychoacoustics of profound hearing impairment. Acta Oto-Laryngol. 1990;Suppl 469:16-22.
- Dubno J, Dirks D. Associations among frequency and temporal resolution and consonant recognition for hearing-impaired listeners. Acta Oto-Laryngol. 1990;Suppl 469:23-29.
- Kuk F, Ludvigsen C. Hearing aid design and fitting solutions for persons with severe to profound losses. Hear Jour. 2000;53(8):29-37.
- Boothroyd A. Profound deafness. In: Tyler R, ed. Cochlear Implants. San Diego: Singular Publishing; 1993:1-34.
- Souza P. Severe Hearing Loss—Recommendations for fitting amplification. Audiology Online, January 19, 2009. Available at: www.audiologyonline.com/articles/article_detail.asp?article_id=2181.
- Sockalingam S, Simonsen, C. Speech Guard: A New Compression Strategy. Oticon Clinical Update. Smørum, Denmark: Oticon A/S; May 2010.
- Simonsen C, Behrens T. A new compression strategy based on a guided level estimator. Hearing Review. 2009;16(13):26-31.
- Sockalingam S, Holmberg M. Evidence of the effectiveness of a spatial noise management system. Hearing Review. 2010;17(9):44-47.
- Lundh P. Auditory modelling applied in hearing aid fitting. In: Vestergaard MD, ed. Collection Volume. Papers from the first seminar on auditory models, Ørsted-DTU Acoustic Technology, Technical University of Denmark; 2001, ISSN-1395-5985; 2001:143-158.
- Supero 413 AZ. Outstanding directional benefit. Phonak Field Study News. Stafa, Switzerland: Phonak AG; March 2004.
Correspondence can be addressed to HR or Donald Schum, PhD, at .
Citation for this article:
Sockalingam R, Lundh P, Schum DJ. Severe to profound hearing loss: What do we know and how do we manage it? Hearing Review. 2011;18(1):30-33.



